Sometime in the late 90s Ruth and I bought a 13 inch Symphonic TV/VCR combo at a warehouse shopping club. This evening, we attempted to watch it only to find that after 3-6 seconds the screen showed "EJECT T" and then the TV shut itself off. The eject function failed, on both the console and the remote. A tape had been put in it earlier that day by a 4 year old, method unknown, and the tape was still in there.
Google can be your friend, but choose carefully. This problem is almost guaranteed to crop up sooner or later with TV/VCR combos made by Funai (who made/make this for Symphonic, Magnavox/Philips, Sears and others). Unfortunately most online complaints either go unanswered or worse, are blamed on a faulty $7.00 sensor assembly which requires a complete teardown of your box. Lots of people found a way to rip the tape out, breaking the VCR and leaving the "EJECT T" problem unfixed. They're hosed. But you aren't.
Here's the solution that worked, and this time I have step by step photos to help you along.
The only tool you'll need is a long philips head screwdriver and your finger. If you have a magnet tool, good.
Unplug the TV and take it to a workroom where you have decent lighting. Place the screen facedown on a padded chair.
On my Symphonic, the rear case is held to the front by five screws: four long ones across the top and bottom, and a fifth, shorter one in a less obvious location. Unscrew them all and keep them nearby. The magnet tool is useful here for removing the screws while the tube is facedown on something soft.
Pull the power cord through the case and set the case aside. Put the chassis on a table so you'll be able to reach the stuck cassette from the front. Do not attempt to loosen the videocassette. If the videotape is around the drum, gently lift it up and away from the drum and capstans. DO NOT TOUCH HAPPY FUN DRUM.
Your problem is a stuck cam, the one responsible for ejecting the tape. Note the tiny motor in the back; its pulley is attached to a small disc which is in turn connected to a giant white gear (the stuck cam). Using your finger, rotate the disc counterclockwise until the tape ejects. DO NOT ATTEMPT TO MOVE THE CAM MANUALLY.
You may have to guide loose videotape out; do so gently.
Put the chassis facedown on the soft chair again and thread the power cable back through the back cover. Screw the back case to the front. You're welcome; that'll be $100.
Wednesday, December 07, 2005
Friday, December 02, 2005
Knoppix to the rescue
My work Optiplex GX260 finally got corrupted while I was in the process of removing old applications and crap from it; my XP upgrade is nigh and it was time to take account of all the useless stuff. While searching my email for something, the PC gave me a BSOD and this time, I was greeted with
Not good. The utility partition AFAIK exists for no reason except to give me serial numbers to read to someone in Bangalore; it doesn't restore NTDETECT and it doesn't restore an MBR. Way to go, Dell. Moreover, the IDE check utility option incorrectly fails to detect the HD.
Fortunately the BIOS allows me to boot CDs, and Knoppix 4.0.2 came to the rescue. It has no difficulty detecting the HD or its partitions. There's a test XP PC next to mine which was being used to evaluate our department's needs; I logged in, created a shared folder, and then...
Well, at home the networking seems more straightforward. Look for the nearest WORKGROUP or MSHOME and dive down. On campus it's a little more complex. KDE's stuff didn't seem to do a good enough job of detecting what I needed. LinNeighborhood OTOH, fed the PC's IP number, was amply capable of finding and mounting the shared folder for me.
Much as I love SLAX and other micro-distros, when you're packing Knoppix, you're pretty well covered on certain networking needs.
NTDETECT failed after the Dell splash screen.Not good. The utility partition AFAIK exists for no reason except to give me serial numbers to read to someone in Bangalore; it doesn't restore NTDETECT and it doesn't restore an MBR. Way to go, Dell. Moreover, the IDE check utility option incorrectly fails to detect the HD.
Fortunately the BIOS allows me to boot CDs, and Knoppix 4.0.2 came to the rescue. It has no difficulty detecting the HD or its partitions. There's a test XP PC next to mine which was being used to evaluate our department's needs; I logged in, created a shared folder, and then...
Well, at home the networking seems more straightforward. Look for the nearest WORKGROUP or MSHOME and dive down. On campus it's a little more complex. KDE's stuff didn't seem to do a good enough job of detecting what I needed. LinNeighborhood OTOH, fed the PC's IP number, was amply capable of finding and mounting the shared folder for me.
Much as I love SLAX and other micro-distros, when you're packing Knoppix, you're pretty well covered on certain networking needs.
Make older Firefox extensions work with 1.5
A number of older FF extensions haven't been updated to work with Tuesday's release of Firefox 1.5 (aka Deer Park RC3). Unfortunately, there's nothing wrong with more than a few of them, but the MoFo Brave New World hype for 1.5 led many developers to play it safe and restrict their extensions to working inside the 1.0.* version range.
Checky, Wayback, FoxyVoice, FireSomething... none of these are dependent on the difference between the 1.0.x and 1.5 cores. How do you fix it?
The developer of Checky explained it for me, and here's the formula you need if you can't wait for your favorite developer to update the extension. As usual, you're taking your computer into your own hands, the secretary will disavow all knowledge, yada yada yada.
First, open Firefox 1.5. Open the Extensions window and visit each of the uncooperative extensions' websites (right-click each to do this). Download the extensions' .xpi files instead of installing them (right-click not left-click) and save them to the desktop. (or, alternately, download them from addons.mozilla.org)
Once they're all downloaded, uninstall the troublesome extensions from FF, and quit, leaving no windows open (like extensions, downloads, etc.). Restart FF and check the extensions to make sure they're gone, and if so, quit again. There's a chunk of file maintenance going on in the background here you don't want to skip.
.XPI files are zipfiles. Here's the process for fixing the "planned obsolescence" built into them.
Change the extension on one of the .xpi files to .zip and unzip it to a folder using your favorite utility (preferably one which retains directory structures). Inside the folder you've created, there'll be an install.rdf file. This is the culprit.
Install.rdf is the file that FF uses to deploy an extension. It tells FF what files there are and where they go, the text and icon of the blurb you see in the Extensions window, etc., etc. It also tells FF which versions of FF it's compatible with, to prevent older versions from installing incompatible extensions and to prevent future versions from installing possibly incompatible ones.
Edit install.rdf in a text editor (not a word processor or WordPad), and search for the following string:
Change the "1.0+" to "1.+" and save the file. Recompress the folder back to another zipfile (with a slightly altered name) and rename the zipfile's extension to .xpi.
Don't double-click it. Open Firefox first, and then open the new .xpi file from Firefox's Open File... You'll still have to wait to verify installation, but the process is the same. Exit Firefox and restart it to see your extension back in business.
And if it crashes your browser, impregnates your girlfriend and makes your dog hate you, at least you were warned.
If you have reason to think that MoFo's going to release a wildly incompatible browser between 1.5 and 2.0, you could change "1.0+" to "1.5+" to make it expire as soon as 1.6 comes out.
Checky, Wayback, FoxyVoice, FireSomething... none of these are dependent on the difference between the 1.0.x and 1.5 cores. How do you fix it?
The developer of Checky explained it for me, and here's the formula you need if you can't wait for your favorite developer to update the extension. As usual, you're taking your computer into your own hands, the secretary will disavow all knowledge, yada yada yada.
First, open Firefox 1.5. Open the Extensions window and visit each of the uncooperative extensions' websites (right-click each to do this). Download the extensions' .xpi files instead of installing them (right-click not left-click) and save them to the desktop. (or, alternately, download them from addons.mozilla.org)
Once they're all downloaded, uninstall the troublesome extensions from FF, and quit, leaving no windows open (like extensions, downloads, etc.). Restart FF and check the extensions to make sure they're gone, and if so, quit again. There's a chunk of file maintenance going on in the background here you don't want to skip.
.XPI files are zipfiles. Here's the process for fixing the "planned obsolescence" built into them.
Change the extension on one of the .xpi files to .zip and unzip it to a folder using your favorite utility (preferably one which retains directory structures). Inside the folder you've created, there'll be an install.rdf file. This is the culprit.
Install.rdf is the file that FF uses to deploy an extension. It tells FF what files there are and where they go, the text and icon of the blurb you see in the Extensions window, etc., etc. It also tells FF which versions of FF it's compatible with, to prevent older versions from installing incompatible extensions and to prevent future versions from installing possibly incompatible ones.
Edit install.rdf in a text editor (not a word processor or WordPad), and search for the following string:
ec8030f7<em:targetapplication>
<description>
<em:id>{ec8030f7-c20a-464f-9b0e-13a3a9e97384}</em:id>
<em:maxversion>1.0+</em:maxversion>
<em:minversion>1.0</em:minversion>
</description>
</em:targetapplication>
The em:id refers to Firefox's own UID, {ec8030f7-c20a-464f-9b0e-13a3a9e97384}. As you can see from the maxversion value in this example, the maximum compatible version is "one point zero with at least one extra character after the zero." Regular expression nerds can guess what's coming next.Change the "1.0+" to "1.+" and save the file. Recompress the folder back to another zipfile (with a slightly altered name) and rename the zipfile's extension to .xpi.
Don't double-click it. Open Firefox first, and then open the new .xpi file from Firefox's Open File... You'll still have to wait to verify installation, but the process is the same. Exit Firefox and restart it to see your extension back in business.
And if it crashes your browser, impregnates your girlfriend and makes your dog hate you, at least you were warned.
If you have reason to think that MoFo's going to release a wildly incompatible browser between 1.5 and 2.0, you could change "1.0+" to "1.5+" to make it expire as soon as 1.6 comes out.
Saturday, November 12, 2005
Making Software Update your bitch
One of the frequent problems I have with Software Update is the quaint notion that a 32M download never chokes. Instead of breaking these larger updates (usually iPod fixes) into smaller manageable downloads to be reassembled and checksummed later, Apple sincerely believes that their users will robotically sit in front of their Macs and retry these choked downloads.
In many cases you can bypass the process by going to Apple:Support:Downloads, and downloading the file directly with your browser (Safari tends to have better luck with resuming large downloads).
Trouble is, not every update is visible there. SU seems to think I need an iPod updater from 9/23/05, but there isn't an equivalent download I can grab it from. What to do, what to do.
Open the Console app, is what. Not Terminal, but Applications/Utilities/Console.app, and attempt the download once more. In all likelihood you'll find the following type of error:
Irritating, eh? But notice now that you have an actual URL to attempt a direct download from. Select the URL, right-click it and a context menu will give you the option of going directly to that URL in your default browser. Perfect, no. Doable, yes.
Edit: Unless Apple's running Apache 2.0 with mod_deflate enabled, this isn't even being sent as a gzip but a regular tarfile. (If you're a *nix n00b, most patches and software that you have to compile yourself tend to be .tar.gz/.tgz files.) OTOH if the file is being compressed server-side live as a gz, that isn't terribly smart either. Right-click, open the tarfile with BOMArchiveHelper and you'll get a folder with another tarfile inside and a signature file; ignore the signature and right-click the second tarfile to unpack it with BOMArchiveHelper. Voila, your update package.
In many cases you can bypass the process by going to Apple:Support:Downloads, and downloading the file directly with your browser (Safari tends to have better luck with resuming large downloads).
Trouble is, not every update is visible there. SU seems to think I need an iPod updater from 9/23/05, but there isn't an equivalent download I can grab it from. What to do, what to do.
Open the Console app, is what. Not Terminal, but Applications/Utilities/Console.app, and attempt the download once more. In all likelihood you'll find the following type of error:
2005-11-12 17:49:02.582 Software Update[2493] session:product:061-2099 didFailWithError:NSError "timed out" Domain=NSURLErrorDomain Code=-1001 UserInfo={
NSErrorFailingURLKey = http://swcdn.apple.com/content/downloads/63/63/061-2099/ FT96wN8RF2sM3TL@FpDNGm9RjbdCfj/iPod2005-09-23.tar;
NSErrorFailingURLStringKey = "http://swcdn.apple.com/content/downloads/63/63/061-2099/ FT96wN8RF2sM3TL@FpDNGm9RjbdCfj/iPod2005-09-23.tar";
NSLocalizedDescription = "timed out";
}
Nov 12 17:55:15 Andrew-Roazens-Computer mDNSResponder: ERROR: read_msg - client version 0x32303035 does not match daemon version 0x00000001
Mac OS X Version 10.4.3 (Build 8F46)
Irritating, eh? But notice now that you have an actual URL to attempt a direct download from. Select the URL, right-click it and a context menu will give you the option of going directly to that URL in your default browser. Perfect, no. Doable, yes.
Edit: Unless Apple's running Apache 2.0 with mod_deflate enabled, this isn't even being sent as a gzip but a regular tarfile. (If you're a *nix n00b, most patches and software that you have to compile yourself tend to be .tar.gz/.tgz files.) OTOH if the file is being compressed server-side live as a gz, that isn't terribly smart either. Right-click, open the tarfile with BOMArchiveHelper and you'll get a folder with another tarfile inside and a signature file; ignore the signature and right-click the second tarfile to unpack it with BOMArchiveHelper. Voila, your update package.
Thursday, November 03, 2005
Obligatory Tiger/SMB gripe and fix
Upgrading to Tiger broke one quizzical thing: I couldn't Samba mount the server our library website lives on. I could mount my staff account on another almost identical Solaris server, but not the library server. Extensive research led me down a blind alley thinking that the library server's authentication was being maintained by a W2K3 server using a proprietary SMB digital signing, but when the sysadmin told me this server does its own authentication, this got puzzling.
I even hunted down the BSD command that OS X uses behind the Apple-K Connect To Server GUI, mount_smbfs, and attempted to tweak every parameter possible in the Terminal. No go.
Hopefully you're here because of a Google search for "Error -36" or something like that. Here's the link to Apple's solution. In a nutshell, passwords can be sent to a server either as plaintext (which other computers on your LAN can packetsniff) or encrypted. Most Samba servers at this point are configured to handle either; the library server (for tech reasons I can't disclose) has to use plaintext.
Prior to Tiger, OS X's Samba authentication was equipped to deal with either kind; because it posed a security hazard, Tiger disables plaintext (unless you follow their instructions and restart your Mac). Apple's helpful response is that we should all force our sysadmins to go with encrypted only. Good luck on that one.
If you're not using Tiger, this won't be an issue. If you're using Tiger and your Samba server accepts encrypted passwords, this won't be an issue. But legacy servers (or servers with a specific reason for using plaintext) will require you to do the tweak mentioned before.
I have no idea whether the code behind this change is open source enough that it could be rewritten so that each entry in the Connect to Server dialog could have a checkmark next to it for encryption and let the software make the connections case by case.
I even hunted down the BSD command that OS X uses behind the Apple-K Connect To Server GUI, mount_smbfs, and attempted to tweak every parameter possible in the Terminal. No go.
Hopefully you're here because of a Google search for "Error -36" or something like that. Here's the link to Apple's solution. In a nutshell, passwords can be sent to a server either as plaintext (which other computers on your LAN can packetsniff) or encrypted. Most Samba servers at this point are configured to handle either; the library server (for tech reasons I can't disclose) has to use plaintext.
Prior to Tiger, OS X's Samba authentication was equipped to deal with either kind; because it posed a security hazard, Tiger disables plaintext (unless you follow their instructions and restart your Mac). Apple's helpful response is that we should all force our sysadmins to go with encrypted only. Good luck on that one.
If you're not using Tiger, this won't be an issue. If you're using Tiger and your Samba server accepts encrypted passwords, this won't be an issue. But legacy servers (or servers with a specific reason for using plaintext) will require you to do the tweak mentioned before.
I have no idea whether the code behind this change is open source enough that it could be rewritten so that each entry in the Connect to Server dialog could have a checkmark next to it for encryption and let the software make the connections case by case.
Wednesday, November 02, 2005
Perl, XML, and XSLT
Our website has a thumbnail of a campus photo which rotates randomly and links to a gallery page of all of the student/faculty-submitted photos. In the past, we would have managed this one of two ways:
The translation of the manifest to the gallery is tailor made for XSLT (XML stylesheet transformation), and strictly speaking a modern browser is capable of doing the translation by itself -- as long as that's the only content on the page. Inserted into the middle of an XHTML document, that's another story. So, it makes sense to have the server manage the XSLT.
In order to that, the Perl we use has to be made aware of XML and XSLT. Good things and bad: first, an XML file really needs a DTD. Why? For one thing, Firefox and IE throw hissies at XML without DTDs even though they don't validate the XML against them. For another, it forces you to define the syntax of your XML. Better yet, XML editors (even Dreamweaver) actually read them and autocomplete your entries. DTDs aren't hard to write once you get used to SGML definition syntax.
Perl still sucks its thumb and sits in the corner, until you integrate XML parsers into it. XML parsers in turn rely on libexpat, whose installation was covered earlier in this blog. As a non-root user, I have to install the XML modules to a local directory; fortunately, previous experience installing FAQ-O-Matic helps here.
Why go to all this trouble? The answer's simpler than it seems. It's a database important enough to need server-side manipulation but not important enough to justify an Oracle table. Currently we're manually editing the XML manifest for the gallery, but with a DTD-based framework for this XML, we can construct webapps for maintaining that database that aren't dependent on a particular language.
With XML::Parser, XML::Simple, and XML::XSLT, we can slurp the database to a Perl dataset, add/edit/remove items and output the resulting dataset back to XML. Should another application need to work with the data, it's there in a friendly, future-extensible format.
- A JavaScript reading an array file, typically a comma-delimited list of filename and metadata, and picking a random array element to output to HTML
- Perl doing the same thing and being SSI included
The translation of the manifest to the gallery is tailor made for XSLT (XML stylesheet transformation), and strictly speaking a modern browser is capable of doing the translation by itself -- as long as that's the only content on the page. Inserted into the middle of an XHTML document, that's another story. So, it makes sense to have the server manage the XSLT.
In order to that, the Perl we use has to be made aware of XML and XSLT. Good things and bad: first, an XML file really needs a DTD. Why? For one thing, Firefox and IE throw hissies at XML without DTDs even though they don't validate the XML against them. For another, it forces you to define the syntax of your XML. Better yet, XML editors (even Dreamweaver) actually read them and autocomplete your entries. DTDs aren't hard to write once you get used to SGML definition syntax.
Perl still sucks its thumb and sits in the corner, until you integrate XML parsers into it. XML parsers in turn rely on libexpat, whose installation was covered earlier in this blog. As a non-root user, I have to install the XML modules to a local directory; fortunately, previous experience installing FAQ-O-Matic helps here.
Why go to all this trouble? The answer's simpler than it seems. It's a database important enough to need server-side manipulation but not important enough to justify an Oracle table. Currently we're manually editing the XML manifest for the gallery, but with a DTD-based framework for this XML, we can construct webapps for maintaining that database that aren't dependent on a particular language.
With XML::Parser, XML::Simple, and XML::XSLT, we can slurp the database to a Perl dataset, add/edit/remove items and output the resulting dataset back to XML. Should another application need to work with the data, it's there in a friendly, future-extensible format.
Friday, October 21, 2005
Palm: 1992-2006?
I got dragged onto the Palm bandwagon in 2000, but the sad fact is that its main advantages over a Filofax are the following in descending order of importance:
Platform historians are going to have a hard time resisting the impulse to paint Palm's history as a flawed copy of the Macintosh. As a former Apple employee, Jeff Hawkins never objected to the comparisons made by the press.
It's an apt parallel to what happened with the original Macintosh, beyond the obvious Motorola 68K/monochrome screen. Design decisions made 10 years before held back the platform, and it took dumping nearly everything that differentiated it in favor of a more standardized OS and hardware to sustain the product name, while carefully maintaining five years' worth of compatibility to make the transition palatable. A faster CPU replaced a 68K and the OS shipping for it was essentially a recompile for the new architecture with a bytecode translator.
Unfortunately they followed Apple's mistakes as well. Spinning off software divisions, releasing too many new models with incompatible hardware and not enough improvements, and taking their momentum over Microsoft for granted.
Ultimately PalmSource made the critical mistake Apple avoided: they thought their future lay in BeOS, wasting a year trying to shoehorn its features into PalmOS before realizing they had zero clout with Palm or its hardware licensees. Cobalt died on the vine. Partners like Handera, Symbol and Tapwave either folded or switched alliances to Windows as laptops got cheaper and smaller and SCO's legal troubles made it relatively clear that Linux was a viable alternative for smartphones.
And Linux is where PalmSource claims PalmOS' future lies, with a new kernel but the same API. Unlike the OS X transition that supplied every Mac user with a fully fledged instance of BSD Unix, the Linux PalmOS won't be a Zaurus running Linux with a recognizable file structure. It's merely an architecture change to make PalmOS easier to port to as-yet-unknown smartphone platforms.
Nevertheless rumors abound that PalmSource's corporate masters have no use for PalmOS.
When everyone got on Wifi, Palm lagged until well after every one of their competitors made it a stock feature. The Windows portable platform rides Microsoft's coattails; iPods feed off iTunes' ubiquity. PalmOS lacks an equivalent lifeline, and Palm's decision to stop supporting MacOS cuts the philosophical tie that founded the company.
The LifeDrive is a solution looking for a problem, and a rushed one at that: a cold restart reformats the hard drive -- and it still can't run any OS except the one burned into it.
The most important lesson geeks and nerds need to take away from the 90s if they didn't cut their teeth in the 80s is this: the commercial computer business is not a meritocracy and it never was.
- fits in my pocket
- holds tons of data without getting larger
- can beep at me to remind me of something
- synchronizes with my desktop computer
- runs software
Platform historians are going to have a hard time resisting the impulse to paint Palm's history as a flawed copy of the Macintosh. As a former Apple employee, Jeff Hawkins never objected to the comparisons made by the press.
It's an apt parallel to what happened with the original Macintosh, beyond the obvious Motorola 68K/monochrome screen. Design decisions made 10 years before held back the platform, and it took dumping nearly everything that differentiated it in favor of a more standardized OS and hardware to sustain the product name, while carefully maintaining five years' worth of compatibility to make the transition palatable. A faster CPU replaced a 68K and the OS shipping for it was essentially a recompile for the new architecture with a bytecode translator.
Unfortunately they followed Apple's mistakes as well. Spinning off software divisions, releasing too many new models with incompatible hardware and not enough improvements, and taking their momentum over Microsoft for granted.
Ultimately PalmSource made the critical mistake Apple avoided: they thought their future lay in BeOS, wasting a year trying to shoehorn its features into PalmOS before realizing they had zero clout with Palm or its hardware licensees. Cobalt died on the vine. Partners like Handera, Symbol and Tapwave either folded or switched alliances to Windows as laptops got cheaper and smaller and SCO's legal troubles made it relatively clear that Linux was a viable alternative for smartphones.
And Linux is where PalmSource claims PalmOS' future lies, with a new kernel but the same API. Unlike the OS X transition that supplied every Mac user with a fully fledged instance of BSD Unix, the Linux PalmOS won't be a Zaurus running Linux with a recognizable file structure. It's merely an architecture change to make PalmOS easier to port to as-yet-unknown smartphone platforms.
Nevertheless rumors abound that PalmSource's corporate masters have no use for PalmOS.
When everyone got on Wifi, Palm lagged until well after every one of their competitors made it a stock feature. The Windows portable platform rides Microsoft's coattails; iPods feed off iTunes' ubiquity. PalmOS lacks an equivalent lifeline, and Palm's decision to stop supporting MacOS cuts the philosophical tie that founded the company.
The LifeDrive is a solution looking for a problem, and a rushed one at that: a cold restart reformats the hard drive -- and it still can't run any OS except the one burned into it.
The most important lesson geeks and nerds need to take away from the 90s if they didn't cut their teeth in the 80s is this: the commercial computer business is not a meritocracy and it never was.
- Better products will be steamrolled by cheaper ones.
- Cheaper equal quality products will be ignored in favor of ones with dumbed down interfaces, European designers and flashy ad campaigns.
- Businesses will choose the bigger company over price, quality or dependable standards, every time.
There's no such thing as an HTML comment, and why that's important
If a comment contains 2 consecutive dashes and its document has an XHTML doctype declaration, Gecko-based browsers like NS 7 and Firefox will show the content after the double dashes. The reason is convoluted but understandable:
Doctypes change the rules. Remember, doctypes are declarations, and declarations define a parser's behavior. In their absence (or in the presence of an HTML 4.0 doctype), browsers typically revert to "quirks mode," which often means they parse HTML using the parser they had in 1999. Add an XHTML doctype, however, and the document will be parsed to stricter guidelines more tightly conforming to XML spec...
...in theory. Gecko browsers (Mozilla/Firefox/Netscape) currently enforce SGML comment syntax in the presence of an XHTML doctype, IE and Opera do not. For now, there isn't much more incentive than there was in 1999; however, as browser based XML/XSLT web apps take off, parsing the XML datasets' custom DTDs will become more necessary, and as hinted before DTDs are just a laundry list of SGML declarations. Given their common heritage and syntax, it's conceivable that a browser's DTD parser and the XHTML/XML/XSLT parser will merge enough to use the same rule for SGML comments in all contexts.
You'll see more SGML in web pages in the future, especially when web servers start using XHTML's correct MIMEtype and stop using HTML's "text/html". This change in MIMEtype triggers even stricter XML parsing in Gecko and Opera, which means that XML-nonconformant content such as JavaScript and CSS inside web pages have to be escaped with <![[CDATA]]> blocks. (If you're using external .css/.js files none of this is an issue.)
Unlike SGML comments, CDATA doesn't hide content but tells the XML parser to ignore it as raw character-based data (similar to how the PRE tag works) and thereby allow JavaScript/CSS operators like < > -- to exist without triggering the error that started this article. Remember, this is 2005 and the number of browsers today which still attempt to render the contents of style/script blocks as text is practically nil, even counting microbrowsers, Lynx, and Netscape 4.7. SGML comment hiding of style/script blocks is unnecessary and deprecated.
- In the SGML spec, <!--this is a comment--> is actually two nested sets of delimiters:
- The <! and > are SGML declaration delimiters. Declarations are usually self-enclosed structural definitions meant for a parser, not content meant for a viewer, and do not look or behave like HTML tags:
<!ELEMENT gallery (imagebase*,image+) --an imagebase child element is optional, but there must be at least one image-- >
Declarations abound in other kinds of SGML documents (such as DTDs), but HTML only demonstrates one in action, the doctype:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">- Inside declarations, double-dashes are the actual comment delimiters (see the example with ELEMENT above).
- Because HTML comes from SGML, its creators saw no reason to reinvent the wheel. Instead of creating an HTML comment tag, they reused an empty SGML declaration with SGML's own declaration comment syntax. There is, in fact, no such thing as an HTML comment tag. When the W3C released the HTML spec, they only reiterated this fine grained point in a separate document comparing SGML and HTML, because they figured everyone was familiar enough with SGML's 15-year-old standard to understand this already. Double-dashes are comment delimiters in several programming languages, and "dash-dash-space-endofline" is the delimiter used by mail programs to separate your message from your sig.
Doctypes change the rules. Remember, doctypes are declarations, and declarations define a parser's behavior. In their absence (or in the presence of an HTML 4.0 doctype), browsers typically revert to "quirks mode," which often means they parse HTML using the parser they had in 1999. Add an XHTML doctype, however, and the document will be parsed to stricter guidelines more tightly conforming to XML spec...
...in theory. Gecko browsers (Mozilla/Firefox/Netscape) currently enforce SGML comment syntax in the presence of an XHTML doctype, IE and Opera do not. For now, there isn't much more incentive than there was in 1999; however, as browser based XML/XSLT web apps take off, parsing the XML datasets' custom DTDs will become more necessary, and as hinted before DTDs are just a laundry list of SGML declarations. Given their common heritage and syntax, it's conceivable that a browser's DTD parser and the XHTML/XML/XSLT parser will merge enough to use the same rule for SGML comments in all contexts.
You'll see more SGML in web pages in the future, especially when web servers start using XHTML's correct MIMEtype and stop using HTML's "text/html". This change in MIMEtype triggers even stricter XML parsing in Gecko and Opera, which means that XML-nonconformant content such as JavaScript and CSS inside web pages have to be escaped with <![[CDATA]]> blocks. (If you're using external .css/.js files none of this is an issue.)
Unlike SGML comments, CDATA doesn't hide content but tells the XML parser to ignore it as raw character-based data (similar to how the PRE tag works) and thereby allow JavaScript/CSS operators like < > -- to exist without triggering the error that started this article. Remember, this is 2005 and the number of browsers today which still attempt to render the contents of style/script blocks as text is practically nil, even counting microbrowsers, Lynx, and Netscape 4.7. SGML comment hiding of style/script blocks is unnecessary and deprecated.
Tuesday, October 18, 2005
Fun with SLAX
OK, I've been dropping off enough copies of Knoppix to earn my Geek Scout badge for the last year. Since I'm running Debian this isn't too surprising; it's a hardcore live demo of Debian Sarge, a quick way to get Linux under your fingernails without commitments.
For a change I thought I'd try the latest SLAX live miniCD image. Slax 5.0.6 is a lot more impressive than the last SLAX distro I checked, 4.2.0. Firstly, the 5.x.y releases are based off the 2.6 kernel, so autoconfiguring your sound is easier. I was impressed to see a good selection of basic Internet apps on it... except the newsreader.
Thunderbird's a great email program. It replaced Eudora on my work desktop months ago and I've never looked back. As a newsgroup reader, it's pretty unimpressive. I never tested it much at work because my employer disabled NNTP access a few years ago so as to keep the servers from melting. At home, it's a different story. Mac users are largely stuck with MT-NewsWatcher, which is adequate but not stupendous and not updated often. Windows users are familiar with a collection of shareware and commercial newsreaders, Forte FreeAgent being a popular choice.
Where Thunderbird lags as a newsreader, ironically, is the concept "modern standards." Binaries newsgroups in the late 80s relied on something called UUencoding for attaching binaries to posts, due to the fact that like email, this method of communication was typically a 7-bit medium attempting to carry 8-bit data. One of its better features is the ability to spread one file out across successive posts. Unfortunately, UUencode lacks native file compression. Enter yEnc. Newsreaders started handling yEnc encoding as early as the mid90s, but the Mozilla group seems to have ignored it as a standard. Moreover, Mozilla's newsreaders can't handle multipart binaries.
Enter Pan. Pan is an open source newsreader whose best features are familiar to users of FreeAgent. Because it's OSS, it's available for most Linux distros. It's not in SLAX, though, and a "carry all your tools in your pocket" CD is incomplete without it.
Before this morning, I never customized a liveCD. Knoppix has a method, but it's unpleasant on resources and speed. SLAX, on the other hand, is designed to be modular and comes with both Windows and Linux tools for rebuilding new ISO images once you've tweaked it.
Pan isn't available as a SLAX 5 module (supposedly SLAX 4 modules are incompatible). However, the SLAX CD comes with a command line utility for converting Slackware .tgz installation files into SLAX .mo modules. The Pan package was converted within a minute, added live to the CD and...
Poop. Turns out it has a GNOME library dependency (gnet). Well, no prob with "Bob," I got the library .tgz, ran it through the same converter, and added it live to the CD, entered pan at a shell prompt and BAM! Pan was up and running. The two .mo files were moved to my PC's hard drive, I restarted the PC, and followed the SLAX instructions for rebuilding the SLAX ISO using the modules. Instead of reburning it I tried to put it through Bochs for testing.
Bochs suchs. I'd been told before to get QEMU and I wasn't disappointed. Far fewer configuration options required, network emulation automatic, and lo and behold, SLAX 5.0.6 with Pan installed. Only downside was, it wasn't part of the KDE Internet submenu. I added Pan to the submenu and the icon bar, then opened a shell and executed a one-line command to export all updates and changes to another .mo module, saved it to the HD, and rebuilt the image once more. (The ISO compress/build process itself is less than five minutes.)
This time, the image booted with Pan in the tray and on the menu. For kicks I added it to the equivalent menus in Fluxbox and cooked the image a third time, burning it to a CD/RW I keep around for this kind of last testing.
Getting a pocket-sized liveCD with basic tools is cool. Getting to customize it without recompiling a kernel is sweet. SLAX takes it one step farther by maintaining a webserver you can log into to save your state to, in case you aren't able to burn customized copies. This pimpslaps Windows "profiles" into last week, folks.
For a change I thought I'd try the latest SLAX live miniCD image. Slax 5.0.6 is a lot more impressive than the last SLAX distro I checked, 4.2.0. Firstly, the 5.x.y releases are based off the 2.6 kernel, so autoconfiguring your sound is easier. I was impressed to see a good selection of basic Internet apps on it... except the newsreader.
Thunderbird's a great email program. It replaced Eudora on my work desktop months ago and I've never looked back. As a newsgroup reader, it's pretty unimpressive. I never tested it much at work because my employer disabled NNTP access a few years ago so as to keep the servers from melting. At home, it's a different story. Mac users are largely stuck with MT-NewsWatcher, which is adequate but not stupendous and not updated often. Windows users are familiar with a collection of shareware and commercial newsreaders, Forte FreeAgent being a popular choice.
Where Thunderbird lags as a newsreader, ironically, is the concept "modern standards." Binaries newsgroups in the late 80s relied on something called UUencoding for attaching binaries to posts, due to the fact that like email, this method of communication was typically a 7-bit medium attempting to carry 8-bit data. One of its better features is the ability to spread one file out across successive posts. Unfortunately, UUencode lacks native file compression. Enter yEnc. Newsreaders started handling yEnc encoding as early as the mid90s, but the Mozilla group seems to have ignored it as a standard. Moreover, Mozilla's newsreaders can't handle multipart binaries.
Enter Pan. Pan is an open source newsreader whose best features are familiar to users of FreeAgent. Because it's OSS, it's available for most Linux distros. It's not in SLAX, though, and a "carry all your tools in your pocket" CD is incomplete without it.
Before this morning, I never customized a liveCD. Knoppix has a method, but it's unpleasant on resources and speed. SLAX, on the other hand, is designed to be modular and comes with both Windows and Linux tools for rebuilding new ISO images once you've tweaked it.
Pan isn't available as a SLAX 5 module (supposedly SLAX 4 modules are incompatible). However, the SLAX CD comes with a command line utility for converting Slackware .tgz installation files into SLAX .mo modules. The Pan package was converted within a minute, added live to the CD and...
Poop. Turns out it has a GNOME library dependency (gnet). Well, no prob with "Bob," I got the library .tgz, ran it through the same converter, and added it live to the CD, entered pan at a shell prompt and BAM! Pan was up and running. The two .mo files were moved to my PC's hard drive, I restarted the PC, and followed the SLAX instructions for rebuilding the SLAX ISO using the modules. Instead of reburning it I tried to put it through Bochs for testing.
Bochs suchs. I'd been told before to get QEMU and I wasn't disappointed. Far fewer configuration options required, network emulation automatic, and lo and behold, SLAX 5.0.6 with Pan installed. Only downside was, it wasn't part of the KDE Internet submenu. I added Pan to the submenu and the icon bar, then opened a shell and executed a one-line command to export all updates and changes to another .mo module, saved it to the HD, and rebuilt the image once more. (The ISO compress/build process itself is less than five minutes.)
This time, the image booted with Pan in the tray and on the menu. For kicks I added it to the equivalent menus in Fluxbox and cooked the image a third time, burning it to a CD/RW I keep around for this kind of last testing.
Getting a pocket-sized liveCD with basic tools is cool. Getting to customize it without recompiling a kernel is sweet. SLAX takes it one step farther by maintaining a webserver you can log into to save your state to, in case you aren't able to burn customized copies. This pimpslaps Windows "profiles" into last week, folks.
Monday, October 03, 2005
MCPAN is for wimps, OR libexpat and I
Hi. If you're like me, you spend most of your time trying to do neat things in Perl.
OK, so no you're not. And frankly, neither am I. However, if you're trying to do XML stuff in Perl, like slurping it into a DOM object and/or doing XSLT transformations, you need XML::XSLT. Unfortunately, it isn't that simple. XML::XSLT depends on XML::Parser, which depends on other modules. XML::XSLT also depends on XML::Parser::Expat, which isn't actually installed by XML::Parser, but libxml. Now, MCPAN will pretend it handles all the dependencies behind the one you're trying to install, but there's a hitch. Two, really.
One, MCPAN is unavailable to non-root users, because it can't do local installs of Perl modules. At home on a Debian Sarge box or my dual G5, this is not a problem. At work, where I'm using my employer's Solaris box, I don't have the privileges to run MCPAN, so I have to manually discover all the dependencies and perl Makefile.PL install each module in turn, by hand from source, being sure to point the installation at a local location.
Two, MCPAN is excellent at handling dependencies -- so long as what it needs are other Perl modules. The heart of XML work in Perl (and Python, for that matter) is a little tiny non-Perl library called Expat. It's a C library which is usually located under /usr/local.
Except that it isn't really a default installation on *nixes. Debian Sarge, yes. OS X/BSD, no. Solaris, yes but not necessarily in /usr/local where XML::Parser expects it, and it certainly isn't part of Windows, either. This is annoying enough that PHP's designers reverse-engineered their own expat-compatible library into PHP.
Moreover, MCPAN ain't apt-get. If it can't handle a dependency, it cries and wets its pants, leaving you to dredge through all its reports in hopes of figuring out what to do. At least apt-get tells you what you might need to do, rather than just suggesting you force the install.
Google "libexpat OS X" to witness the wailing and moaning of the damned (Perl, Python and others) unable to understand how they were left behind. Life is hell.
If you're one of them and you found this blog, here's what you have to do. First off, log in as root on your Mac and open a browser. Go here to get the source code archive for expat. You're going to do this old-school and compile it yourself. Relax, I'll hold your hand through this.
Now that you have the tar.gz file on your desktop, resist the impulse to double-click it. If you have, delete the folder. Open the Terminal:
That's it. Go back to MCPAN and install XML::XSLT; the rest should fall into place.
[As nice as the OS X and Stuffit utilities are for decompressing tar.gz, gunzip and tar do what *nixes expect down to the letter, and desktop decompression utilities have been known to do strange things to filenames. WinZip, for example, creates the expat folder seemingly flawlessly, but your shell will insist to high heaven that there's no configure file to ./ even as you see it there.]
Fink's the OS X version of apt-get. The downside to Fink is that like apt-get, you're stuck with what's available in the current repository, and worse, each new release of OS X has unpleasant repercussions for Fink. When Debian has a new release, the repository tends to be ready; when OS X has a new release, there's endless bitching about what's broken in Fink.
FWIW, I ran the MCPAN XML::XSLT installs on Debian Sarge and Tiger simultaneously. Debian handled it flawlessly, only occasionally asking yes/no questions to which the Enter key was sufficient. OS X tried to do the same, but gargled on its own vomit until I manually installed expat and started over. Ironically, when I tried to use perldoc to verify that XML::XSLT was installed on Linux, perldoc wasn't there and had to be installed using apt-get.
It's conceivable that a default install of Debian doesn't have expat, either. Nevertheless, this thing should be integrated into all *nix default installs. MCPAN should be as good as apt-get.
OK, so no you're not. And frankly, neither am I. However, if you're trying to do XML stuff in Perl, like slurping it into a DOM object and/or doing XSLT transformations, you need XML::XSLT. Unfortunately, it isn't that simple. XML::XSLT depends on XML::Parser, which depends on other modules. XML::XSLT also depends on XML::Parser::Expat, which isn't actually installed by XML::Parser, but libxml. Now, MCPAN will pretend it handles all the dependencies behind the one you're trying to install, but there's a hitch. Two, really.
One, MCPAN is unavailable to non-root users, because it can't do local installs of Perl modules. At home on a Debian Sarge box or my dual G5, this is not a problem. At work, where I'm using my employer's Solaris box, I don't have the privileges to run MCPAN, so I have to manually discover all the dependencies and perl Makefile.PL install each module in turn, by hand from source, being sure to point the installation at a local location.
Two, MCPAN is excellent at handling dependencies -- so long as what it needs are other Perl modules. The heart of XML work in Perl (and Python, for that matter) is a little tiny non-Perl library called Expat. It's a C library which is usually located under /usr/local.
Except that it isn't really a default installation on *nixes. Debian Sarge, yes. OS X/BSD, no. Solaris, yes but not necessarily in /usr/local where XML::Parser expects it, and it certainly isn't part of Windows, either. This is annoying enough that PHP's designers reverse-engineered their own expat-compatible library into PHP.
Moreover, MCPAN ain't apt-get. If it can't handle a dependency, it cries and wets its pants, leaving you to dredge through all its reports in hopes of figuring out what to do. At least apt-get tells you what you might need to do, rather than just suggesting you force the install.
Google "libexpat OS X" to witness the wailing and moaning of the damned (Perl, Python and others) unable to understand how they were left behind. Life is hell.
If you're one of them and you found this blog, here's what you have to do. First off, log in as root on your Mac and open a browser. Go here to get the source code archive for expat. You're going to do this old-school and compile it yourself. Relax, I'll hold your hand through this.
Now that you have the tar.gz file on your desktop, resist the impulse to double-click it. If you have, delete the folder. Open the Terminal:
$ cd ~/Desktop $ ls expat-1.95.8.tar.gz Applications [yada yada] $ gunzip expat-1.95.8.tar.gz $ tar -xvf expat-1.95.8.tar $ cd expat-1.95.8 $ ./configure $ make $ make install
That's it. Go back to MCPAN and install XML::XSLT; the rest should fall into place.
[As nice as the OS X and Stuffit utilities are for decompressing tar.gz, gunzip and tar do what *nixes expect down to the letter, and desktop decompression utilities have been known to do strange things to filenames. WinZip, for example, creates the expat folder seemingly flawlessly, but your shell will insist to high heaven that there's no configure file to ./ even as you see it there.]
Fink's the OS X version of apt-get. The downside to Fink is that like apt-get, you're stuck with what's available in the current repository, and worse, each new release of OS X has unpleasant repercussions for Fink. When Debian has a new release, the repository tends to be ready; when OS X has a new release, there's endless bitching about what's broken in Fink.
FWIW, I ran the MCPAN XML::XSLT installs on Debian Sarge and Tiger simultaneously. Debian handled it flawlessly, only occasionally asking yes/no questions to which the Enter key was sufficient. OS X tried to do the same, but gargled on its own vomit until I manually installed expat and started over. Ironically, when I tried to use perldoc to verify that XML::XSLT was installed on Linux, perldoc wasn't there and had to be installed using apt-get.
It's conceivable that a default install of Debian doesn't have expat, either. Nevertheless, this thing should be integrated into all *nix default installs. MCPAN should be as good as apt-get.
Tuesday, September 27, 2005
A few observations on Debian Linux
About a year ago I bought a campus surplus Dell Optiplex GX1 (PIII) to see how well Debian GNU/Linux would work out as a home PC, and whether I could successfully maintain it as a dual-boot box (NAU staffers can get Windows XP for $10). Sometimes it's good to see how another product performs, even if it's not your preferred platform (like, say, a certain blog platform).
Knowing that Windows won't install itself into a secondary partition, I let the Windows installer partition the HD using recommendations a Red Hat user had posted somewhere. Roughly speaking, Windows got 40% NTFS with a swapfile partition of 5% and a 5% FAT32 partition and left the rest alone. The Debian Sarge (then the testing release) installer split the remaining 50% into 45% ext2 and 5% swapfile.
The 5% FAT32 partition was created specifically as Switzerland: a neutral space mounted by both OSes for the purpose of sharing files between them. For example, the login user icon that Windows uses for Administrator and Debian uses for root is the same image file, on this partition. Firefox on both OSes point their bookmarks at this partition; add a bookmark in one and it's visible to the other. Remember, Debian's NTFS support at this point is largely read-only, and putting Windows XP in a FAT32 partition is kinda dumb.
For the most part, everything just works. Because the Epson inkjet in our household is connected to the Mac, the Mac's printer sharing is done through CUPS. To a Windows PC, this means it has to be mounted as a color PostScript printer. Linux finds it on its own and automagically configures it correctly (because it also uses CUPS). Moreover, it also figured out that the Mac had an internal fax modem.
Not everything worked out of the box, however. SMB doesn't work until several components are installed: LISA, SMB, etc. This is disappointing because most Debian-based LiveCDs do a much more aggressive job of detecting hardware and network resources at startup (e.g. Knoppix and Ubuntu).
Yesterday, I went to the local computer shop and picked out a CD-RW/DVD-ROM drive. One thing about the GX1 towers, they come with a lot of empty space and 2 extra bays (which doesn't count the space the two internal HDs use). Everything was in order, the primary CD-ROM's ribbon cable had another connector crimped into it and there were enough power connectors inside to go around. Pull out the sled, screw the drive to it, slide it back in and connect the connectors. Reboot.
Here's where Debian disappointed particularly. As soon as XP rebooted it discovered the drive and configured it. VLC was playing my homebrewed DVDs peachy-keen (however, until I install PowerDVD, I can kiss CSS-encrypted discs goodbye). I rebooted into Sarge, and -- nothing.
The startup log indicated that it knew there was a /dev/hdd, at the console entering more /dev/hdd resulted in a binary dump of the DVD's contents, but Debian didn't do the simplest thing: it didn't configure the device as a mounted drive. To make sure it wasn't a kernel issue, I booted the PC from a recent liveCD, and it detected and mounted the drive fine. Totem played the disc, no questions asked.
Lots of idiot googling suggested it was my responsibility to manually edit /etc/fstab to add the entry. It only worked when I pointed it at /cdrom0 and rebooted. Currently, nothing is writing to the drive, but I'm trying first with FOSS on both platforms (burnatonce on XP).
When Sarge became stable and I changed the repository info to reflect this, nothing bad happened. However, when I modified the kernel to the latest version available for stable, the GRUB settings conveniently deleted the first entry which boots Windows. I manually edited it back in; everything fine. When I realized the new kernel was still a 386 kernel and my PIII was a 686, I got the 686 kernel -- and the same thing happened.
After the 686 kernel was installed, the Debian graphical login stopped working. The keyboard was useless except for a few numeric digits and the Caps lock key wasn't toggling the LED indicator. More googling indicated a separate config had been corrupted, and a keyboard option four characters long had to be edited back into the config.
The Vortex au8820 audio chip was never detected by Debian at install, and all attempts to modprobe/insmod were in vain. After the 2.6 kernel upgrade I installed alsaconf, ran it and it correctly found the hardware. FWIW Knoppix is equally dense about this audio chip and requires the same fix; Ubuntu liveCDs find it automatically.
I like the challenge of hacking a system to get it to do something. I don't like keeping an internal diary of the things I'd have to do to someone else's PC to make a usable Debian partition, esp. when most liveCDs already do these things, and gracefully.
It's a nice distro. I prefer KDE to Gnome and so does Knoppix. Gnoppix is cute, but it isn't really the Knoppix distro with a different desktop environment. However, Debian's biggest competition right now is Ubuntu, and a chunk of Ubuntu's advantage is the degree to which it will hold your hand on the basics. More than anything, this is what defines a desktop OS.
I've been fortunate; I've never had to recompile my kernel to do something, and I have Sarge running on two PCs in different environments. Nevertheless, Sarge is lazy about detecting and configuring peripherals and network resources, beyond finding and making DHCP connections. The installer never tested the audio, and it took four hours on a DSL connections to grab the basic distro. Debian's on to something with the notion that CD-based installs are dead; however, if Klaus Knopper can fit a 9Gb Debian Sarge distro onto a DVD, maybe the writing's on the wall.
Will I switch to (K)Ubuntu? Probably not. Ubuntu's shtick is making Sid into a usable product, but the price is steep: Debian releases are named after Toy Story characters, and Sid is the name permanently reserved for the unstable release (Sid=Still In Development). Basing a distro on the least fixed, most experimental release just to have the most cutting edge features is a great idea, but it's difficult to dispel internal FUD about incompatibilities. There are stories of people who switched back to Sarge when something went wrong; Ubuntu is in all likelihood going to be the Fisher-Price My First Linux for desktop n00bs who aren't interested in building servers, unless Debian can suck up the pride and integrate Ubuntu's better user experience.
Someone said it best on OSNews: Ubuntu doesn't fork Debian, it forks Debian's release schedule. Cairo is ready for Sarge, but Sarge isn't ready for Cairo while most other current distros (Ubuntu included) already have it. For the uninitiated, OS X's graphics engine is a combination of Display PostScript and GPU processing; Cairo is Linux's closest equivalent being bound to the various graphic APIs available for Linux. The implications are applications which (like Flash) think in vector-based objects rather than processing bitmaps, exploiting the power of GPUs. If Debian users have to wait a year or more for a new library to be integrated into the next stable release, it could cause defections. Then again, Debian is a distro aimed at the most diverse number of platforms out there; Ubuntu is available in chocolate and vanilla, where the hardware doesn't differ that much.
I don't want to see Debian turn into Ubuntu, but I would like Debian to be more aware of my resources, esp. if they change after installation. If a major new library is available, and it can be tested across platforms, add it to the repository. Unless Debian can pass itself off as a desktop OS, they're leaving a vacuum for someone else to fill, and Ubuntu seems pretty comfortable in that place.
[edit: the day after I wrote this blog entry I discovered that Debian Sarge in fact has a 2-DVD-based installer, available by http/ftp or torrent.]
[correction: when I built my dual-boot box, I stupidly made the Debian root partition not only a paltry 6Gb and the share partition 15Gb, but I let the installer put the root partition at the physical end of the disk. This means that QTparted and GNU parted can't grow it backwards even if I shrink the previous partition.]
Knowing that Windows won't install itself into a secondary partition, I let the Windows installer partition the HD using recommendations a Red Hat user had posted somewhere. Roughly speaking, Windows got 40% NTFS with a swapfile partition of 5% and a 5% FAT32 partition and left the rest alone. The Debian Sarge (then the testing release) installer split the remaining 50% into 45% ext2 and 5% swapfile.
The 5% FAT32 partition was created specifically as Switzerland: a neutral space mounted by both OSes for the purpose of sharing files between them. For example, the login user icon that Windows uses for Administrator and Debian uses for root is the same image file, on this partition. Firefox on both OSes point their bookmarks at this partition; add a bookmark in one and it's visible to the other. Remember, Debian's NTFS support at this point is largely read-only, and putting Windows XP in a FAT32 partition is kinda dumb.
For the most part, everything just works. Because the Epson inkjet in our household is connected to the Mac, the Mac's printer sharing is done through CUPS. To a Windows PC, this means it has to be mounted as a color PostScript printer. Linux finds it on its own and automagically configures it correctly (because it also uses CUPS). Moreover, it also figured out that the Mac had an internal fax modem.
Not everything worked out of the box, however. SMB doesn't work until several components are installed: LISA, SMB, etc. This is disappointing because most Debian-based LiveCDs do a much more aggressive job of detecting hardware and network resources at startup (e.g. Knoppix and Ubuntu).
Yesterday, I went to the local computer shop and picked out a CD-RW/DVD-ROM drive. One thing about the GX1 towers, they come with a lot of empty space and 2 extra bays (which doesn't count the space the two internal HDs use). Everything was in order, the primary CD-ROM's ribbon cable had another connector crimped into it and there were enough power connectors inside to go around. Pull out the sled, screw the drive to it, slide it back in and connect the connectors. Reboot.
Here's where Debian disappointed particularly. As soon as XP rebooted it discovered the drive and configured it. VLC was playing my homebrewed DVDs peachy-keen (however, until I install PowerDVD, I can kiss CSS-encrypted discs goodbye). I rebooted into Sarge, and -- nothing.
The startup log indicated that it knew there was a /dev/hdd, at the console entering more /dev/hdd resulted in a binary dump of the DVD's contents, but Debian didn't do the simplest thing: it didn't configure the device as a mounted drive. To make sure it wasn't a kernel issue, I booted the PC from a recent liveCD, and it detected and mounted the drive fine. Totem played the disc, no questions asked.
Lots of idiot googling suggested it was my responsibility to manually edit /etc/fstab to add the entry. It only worked when I pointed it at /cdrom0 and rebooted. Currently, nothing is writing to the drive, but I'm trying first with FOSS on both platforms (burnatonce on XP).
When Sarge became stable and I changed the repository info to reflect this, nothing bad happened. However, when I modified the kernel to the latest version available for stable, the GRUB settings conveniently deleted the first entry which boots Windows. I manually edited it back in; everything fine. When I realized the new kernel was still a 386 kernel and my PIII was a 686, I got the 686 kernel -- and the same thing happened.
After the 686 kernel was installed, the Debian graphical login stopped working. The keyboard was useless except for a few numeric digits and the Caps lock key wasn't toggling the LED indicator. More googling indicated a separate config had been corrupted, and a keyboard option four characters long had to be edited back into the config.
The Vortex au8820 audio chip was never detected by Debian at install, and all attempts to modprobe/insmod were in vain. After the 2.6 kernel upgrade I installed alsaconf, ran it and it correctly found the hardware. FWIW Knoppix is equally dense about this audio chip and requires the same fix; Ubuntu liveCDs find it automatically.
I like the challenge of hacking a system to get it to do something. I don't like keeping an internal diary of the things I'd have to do to someone else's PC to make a usable Debian partition, esp. when most liveCDs already do these things, and gracefully.
It's a nice distro. I prefer KDE to Gnome and so does Knoppix. Gnoppix is cute, but it isn't really the Knoppix distro with a different desktop environment. However, Debian's biggest competition right now is Ubuntu, and a chunk of Ubuntu's advantage is the degree to which it will hold your hand on the basics. More than anything, this is what defines a desktop OS.
I've been fortunate; I've never had to recompile my kernel to do something, and I have Sarge running on two PCs in different environments. Nevertheless, Sarge is lazy about detecting and configuring peripherals and network resources, beyond finding and making DHCP connections. The installer never tested the audio, and it took four hours on a DSL connections to grab the basic distro. Debian's on to something with the notion that CD-based installs are dead; however, if Klaus Knopper can fit a 9Gb Debian Sarge distro onto a DVD, maybe the writing's on the wall.
Will I switch to (K)Ubuntu? Probably not. Ubuntu's shtick is making Sid into a usable product, but the price is steep: Debian releases are named after Toy Story characters, and Sid is the name permanently reserved for the unstable release (Sid=Still In Development). Basing a distro on the least fixed, most experimental release just to have the most cutting edge features is a great idea, but it's difficult to dispel internal FUD about incompatibilities. There are stories of people who switched back to Sarge when something went wrong; Ubuntu is in all likelihood going to be the Fisher-Price My First Linux for desktop n00bs who aren't interested in building servers, unless Debian can suck up the pride and integrate Ubuntu's better user experience.
Someone said it best on OSNews: Ubuntu doesn't fork Debian, it forks Debian's release schedule. Cairo is ready for Sarge, but Sarge isn't ready for Cairo while most other current distros (Ubuntu included) already have it. For the uninitiated, OS X's graphics engine is a combination of Display PostScript and GPU processing; Cairo is Linux's closest equivalent being bound to the various graphic APIs available for Linux. The implications are applications which (like Flash) think in vector-based objects rather than processing bitmaps, exploiting the power of GPUs. If Debian users have to wait a year or more for a new library to be integrated into the next stable release, it could cause defections. Then again, Debian is a distro aimed at the most diverse number of platforms out there; Ubuntu is available in chocolate and vanilla, where the hardware doesn't differ that much.
I don't want to see Debian turn into Ubuntu, but I would like Debian to be more aware of my resources, esp. if they change after installation. If a major new library is available, and it can be tested across platforms, add it to the repository. Unless Debian can pass itself off as a desktop OS, they're leaving a vacuum for someone else to fill, and Ubuntu seems pretty comfortable in that place.
[edit: the day after I wrote this blog entry I discovered that Debian Sarge in fact has a 2-DVD-based installer, available by http/ftp or torrent.]
[correction: when I built my dual-boot box, I stupidly made the Debian root partition not only a paltry 6Gb and the share partition 15Gb, but I let the installer put the root partition at the physical end of the disk. This means that QTparted and GNU parted can't grow it backwards even if I shrink the previous partition.]
Monday, July 25, 2005
Check All/Uncheck All JavaScript buttons: Take 2
The trouble with JavaScript widgets is that they aren't self-aware, and they're typically designed by someone who has minimal assumptions about the page they're on (or the browsers they're compatible with). DHTML magnifiers assume the content they're meant to magnify is safely at the top of the page, and break when it isn't. Check All/Uncheck All button scripts don't account for the possibility of subranges. And so on and so forth.
One of our upcoming pages on the site redo is a form with several checkboxes all within the same name group, but subdivided into academic disciplines. The CGI is still expecting the same form data it did before these C/U buttons were added.
The basic script for checking all boxes goes as follows: an onclick handler passes the entire Input collection to a script, which loops over it and sets the input.checked property to true or false, based on a flag which is flipped at the end of the routine, right before toggling the button text. The trouble here is subranges.
Fortunately, the subdivisions are separate tables which can be given IDs: the onclick handler sends instead the ID, and walking the DOM tree, the script collects just the inputs which are children of that ID.
Here comes the complexity. The Check All/Uncheck All buttons are useless and confusing to scriptless UAs. Being associated with black magic, they should be inserted dynamically using black magic. In The Good Old Days we would merrily employ document.write or innerHTML to insert the content.
Well, when you serve pages as XHTML, those methods disappear. Poof. And the reason is simple. XHTML is supposed to be valid XML. If a script can insert any text string into a page, it can break the XML. So, instead we create the C/U button by constructing an input element, feeding it the necessary attributes, and finding an appropriate node to insert it into. 'tdid' is the ID for the table, and 'garth' is the ID of the TH element whose contents the button will be appended to.
The theory is that all elements will be manipulated through setAttribute and removeAttribute, and tag specific methods will be deprecated. The reality is that IE 5/6 has a somewhat incomplete model for which attributes this works. People discovered that in IE, setAttribute didn't like events. So, we're attaching the check function directly to the object's onclick method.
If you were paying attention above, you'll notice the check function could have used setAttribute to check the boxes and removeAttribute to uncheck them, instead of a tag specific method. The reason it doesn't is because IE can't remove the checked attribute. It just can't. It can, however, set the attribute value to "" which unchecks the box... except in every other browser, which follow W3C spec on arguments and formerly collapsed attributes. If any value, even a blank one, is attributed to a collapsed attribute in HTML code, it's considered to be the same as the collapsed attribute in HTML 3. FF and Opera treat setting the value="" as checking the box.
The only way to do it in JavaScript is to pack both methods into an if/then subroutine, with the IE method first and the DOM method second. Forked code sucks.
Oh, and why check the input elements for whether they're checkboxes? The C/U buttons are themselves input elements and should be excluded. Currently, no browser complains when you manipulate the checked property of an input element which isn't supposed to have one (even in XHTML mode), but it isn't inconceivable this too will someday break.
One of our upcoming pages on the site redo is a form with several checkboxes all within the same name group, but subdivided into academic disciplines. The CGI is still expecting the same form data it did before these C/U buttons were added.
The basic script for checking all boxes goes as follows: an onclick handler passes the entire Input collection to a script, which loops over it and sets the input.checked property to true or false, based on a flag which is flipped at the end of the routine, right before toggling the button text. The trouble here is subranges.
Fortunately, the subdivisions are separate tables which can be given IDs: the onclick handler sends instead the ID, and walking the DOM tree, the script collects just the inputs which are children of that ID.
function check(ctainer) {
var field = document.getElementById(ctainer).getElementsByTagName("input");
for (i = 0; i < field.length; i++) {
if (field[i].type.toLowerCase()=="checkbox") {field[i].checked = !checkflag;}
}
checkflag = !checkflag;
return (checkflag) ? "Uncheck All":"Check All";
}Here comes the complexity. The Check All/Uncheck All buttons are useless and confusing to scriptless UAs. Being associated with black magic, they should be inserted dynamically using black magic. In The Good Old Days we would merrily employ document.write or innerHTML to insert the content.
Well, when you serve pages as XHTML, those methods disappear. Poof. And the reason is simple. XHTML is supposed to be valid XML. If a script can insert any text string into a page, it can break the XML. So, instead we create the C/U button by constructing an input element, feeding it the necessary attributes, and finding an appropriate node to insert it into. 'tdid' is the ID for the table, and 'garth' is the ID of the TH element whose contents the button will be appended to.
function makeButt(tdid,garth) {
var l=document.createElement('input');
l.setAttribute('type','button');
l.setAttribute('value','Check All');
l.onclick = function() { this.value=check(garth); }
document.getElementById(tdid).appendChild(l);
}The theory is that all elements will be manipulated through setAttribute and removeAttribute, and tag specific methods will be deprecated. The reality is that IE 5/6 has a somewhat incomplete model for which attributes this works. People discovered that in IE, setAttribute didn't like events. So, we're attaching the check function directly to the object's onclick method.
If you were paying attention above, you'll notice the check function could have used setAttribute to check the boxes and removeAttribute to uncheck them, instead of a tag specific method. The reason it doesn't is because IE can't remove the checked attribute. It just can't. It can, however, set the attribute value to "" which unchecks the box... except in every other browser, which follow W3C spec on arguments and formerly collapsed attributes. If any value, even a blank one, is attributed to a collapsed attribute in HTML code, it's considered to be the same as the collapsed attribute in HTML 3. FF and Opera treat setting the value="" as checking the box.
The only way to do it in JavaScript is to pack both methods into an if/then subroutine, with the IE method first and the DOM method second. Forked code sucks.
Oh, and why check the input elements for whether they're checkboxes? The C/U buttons are themselves input elements and should be excluded. Currently, no browser complains when you manipulate the checked property of an input element which isn't supposed to have one (even in XHTML mode), but it isn't inconceivable this too will someday break.
Tuesday, July 12, 2005
Potentially overlooked CSS tips
A friend of mine who does vids just bought her first set of CSS primers and plans retooling her website. In honor of her recent birthday I'll pass along a wordy but useful set of tips. If she values the observations of three years dancing in landmines, she'll pay attention.
Prologue: in 2002, I started an unrequested skunkworks project of redesigning a tables-based, JavaScript-rollover-infested, accessibility hobbled website from HTML4 to XHTML/CSS. The next year a formal call for a makeover was requested and my R&D was implemented; the results of that redesign are the Cline Library website. Links below to the current 2005 revision:
CSS Padawan 101:
Prologue: in 2002, I started an unrequested skunkworks project of redesigning a tables-based, JavaScript-rollover-infested, accessibility hobbled website from HTML4 to XHTML/CSS. The next year a formal call for a makeover was requested and my R&D was implemented; the results of that redesign are the Cline Library website. Links below to the current 2005 revision:
- Home page
- Colorado Plateau Digital Archives Search
- Special Collections and Archives Colorado Plateau
- Find Articles
CSS Padawan 101:
- It's natural for a beginning CSS developer to wrap everything in classed DIVs/SPANs, and to overdo it. Over time, reexamine your code and look for places where specificity would do the job better with less code. Where my pages seemingly diverge from this advice, it's because of complex inheritance issues: list elements on the newblue homepage behave in sometimes radically different ways depending on their section and purpose. The choices are to stick class attributes on all of them (revisiting the HTML4 formatting tag soup and lengthening the page code) or to wrap them in DIVs with IDs which guarantee separate behavior.
- DTDs matter when it comes to how browsers treat your CSS. Even if you're a diehard HTML 4.0 enthusiast, leaving out any DTD ensures browsers play in 'quirks mode,' a genteel euphemism for 'browser regresses to flaws of previous major version.' I favor XHTML 1.0/Transitional as a good place to work from.
- DTDs affect more than just CSS. Older DHTML JavaScripts manipulate object size/position values with unit-less integer values (e.g. 'property.style.top=300' instead of 'property.style.top=300px'). Just as you can't do this with CSS values in the presence of a DTD, IE is appropriately fierce about throwing errors in JavaScript when an XHTML/Transitional DTD is present and units are not, and older scripts may have to be rewritten. Better solutions are to find more current, DOM-friendly versions/alternatives or dump JavaScript altogether.
- An XML prolog will bork the DTD in IE 6. Get rid of it. If your HTML editor automatically inserts an XML prolog at the top of the file, IE 6 will ignore the DTD below it and throw your browser into quirks mode. This didn't matter with the first layout when IE 5 was king, but it matters plenty with newblue: this 3-column liquid layout is a simple bit of CSS, but in quirks mode IE 6 reverts to pretending it's IE 5 which never understood that simple bit of CSS. Until all mainstream browsers expect websites to be served as XML with an XML MIMEtype, that XML prolog is useless and delete it. Even the W3C validator doesn't balk at its absence.
- "It works in IE" is a terrible fucking excuse for anything. I test against several browsers knowing full well their combined marketshare is less than 15% of our users(although it's a growing share), because coding to standards is a smaller headache longterm than coding to browsers. From experience I speak, padawan. In order for IE 7 to get through this they will have to rewrite a lot more of their renderer than I think they have the will, brains or balls to do.
- Opera isn't the yardstick it used to be on web standards. When they entered the business they made themselves felt as a company more concerned with standards than IE emulation: their insistence that the correct alternative to BODY MARGIN="0" is body{padding:0px;} rather than the {margin:0px;} all other browsers use is still the case with Op8. OTOH Firefox is killing their marketshare outside embedded and certain niche markets, and their product which once had IE UA spoofing as an option now defaults to it, and more critically, slavishly imitates IE's default HTML rendering and proprietary JavaScript properties. They took being shut out of MSN hard. Don't get me wrong, it's still a damn fine browser, with probably the best accessibility integration for Windows (and free integration at that), but at this point the best their fans can say is "Look at the beautiful pluma--er, mouse gestures!" It's still important to test against, since they still claim to use the same render engine in all their products (including embedded).
- Mozilla/FF/NS isn't God either. Form elements like buttons and checkboxes should be resizable, colorable, etc. with CSS, and IE gets it. The Gecko engine does not. But as of this writing it's still the first place to test modern technologies like CSS2.
- No matter what Apple tells you, Safari and KHTML (Konqueror) are not interchangeable terms. Safari relies more and more heavily on WebKit technology which is not open source, and Dave Hyatt is unapologetic about it. Major improvements in either product's renderer should appear in the other eventually, but only if they're in the KHTML portion. Speaking as someone who uses Konqueror, it's an excellent file browser. As a Web browser, it's an excellent argument for bundling Firefox in Linux distros. And no matter what the Safari user-agent string says, KHTML is NOT "Gecko-like." The Apple tech who put that into Safari is part of the witless protection program now.
- Current screen readers do not respect 'media=' attributes. This means that the content you meant to hide from visual browsers using display:none; in a stylesheet aimed at media="screen" won't get spoken in aural browsers either, even if you have a separate aural stylesheet overriding the selector. Those of us who deal with the vendors of these "solutions" are livid that the one sole attribute in HTML meant for their consumption and processing is ignored, and we fervently pray Freedom Scientific finds itself sued by the Australian/British courts for flouting it. It's not much of a secret that FS is run by Visual Basic hackers cocksure that Microsoft will buy them out and integrate it into Windows. Again, visibility:hidden means "render a blank space the same size as the content." Display:none according to W3C specs actually means "remove content from HTML stream" (although not the DOM).
- Lynx is not a bad choice for crude accessibility testing, and it's still a decent choice for mobile device testing.
- Just as you're being told to avoid using fixed (e.g. px) units for fonts, consider eliminating them for paddings and margins on a case by case basis. Page margins are a good place for fixed units; paddings between LI elements are not, no matter how many years of Microsoft word stylesheet have told us (then again, we never had scalable units as an option). Ems make good neighbors.
- This is old hat by now, but Navbars should be the bottom of your HTML document. People with screenreaders detest hearing them repeated at the beginning of every page, and skip links are a holdover from purely linear HTML rendering. Moreover, people reading your site on mobile devices will thank you for putting content first. All the above examples on our site use absolute positioning to move the navbar where the sight-unimpaired expect it (top and/or left). BION, there was a time when this technique was considered controversial.
- CSS hacks suck for several reasons. First, they presuppose that the parsing errors they exploit will not be patched inside a major release. Secondly, they screw with validators. Thirdly, they screw with integrated web development packages which treat CSS files as valid data structures. Most serious IE hacks are aimed at IE 5.x problems, and local/national stats on 5.x usage are somewhere around that of Netscape 4 users. Pages should degrade gracefully, but if they can't because one end-of-life browser has a seriously broken model, cut your losses.
- IE and Opera arbitrarily default to sizing the text inside text-based form controls at 85% the container font-size whereas Gecko and others use 100%. This means that if those form elements have padding defined in scalable units (ems/exes) that spacing is calculated on the size of the text in those elements, not the parent container's. Without devoting three paragraphs to explain why, it's a good idea for accessibility and consistency to formally declare INPUT,SELECT {font-size:100%;} if you plan to design CSS form layouts which gracefully scale for visual disabilities. Trust me on this one.
- Join css-discuss. It's as much for n00bs as pros, and you'll get exposed to some cutting-edge stuff. Before you know it, you'll be helping people, too.
Thursday, June 16, 2005
M'man, Barry.
In high school I was fortunate enough to take classes under Barry Moser. Read this interview with him.
Sunday, June 12, 2005
Whither Classic?
Edit: I should have read Daring Fireball more closely. Classic is apparently dead in the water, according to both the Apple Universal Binary Guidelines and whatever sources JG has. Also, apologies to John Gruber for unintentially pilfering his blog's subtitle. I've changed mine to something interimish.
One serious implication for OS x86: Classic. Darwin's platform independent, and Rosetta is there to handle PPC code before handing it over to the Darwin/OS X API.
Classic involves 68K emulation, and up until now it's gotten a free ride because PPCs run 68K code faster than native. How's Classic going to work in Teh New Architecture?
Apple has three possibilities.
Sometimes, Steve, you gotta do something just because it's cool to be able to, and being able to sell potential switchers on a box that runs not just the last five years' worth of apps but the last ten or fifteen is damned sweet. No one much gives a damn how you do it.
One serious implication for OS x86: Classic. Darwin's platform independent, and Rosetta is there to handle PPC code before handing it over to the Darwin/OS X API.
Classic involves 68K emulation, and up until now it's gotten a free ride because PPCs run 68K code faster than native. How's Classic going to work in Teh New Architecture?
Apple has three possibilities.
- Keep the compiled PPC emulation code in OS X as a legacy chunk, and let Rosetta translate PPC code emulating 68K code, praying we don't care about performance. Emulation inside translation; this is asking a lot of a system.
- Assume Apple licensed more than just an x86 translation library from Transitive, and OS x86's Classic mode uses direct 68K to x86 translation. Why shouldn't they? The challenge of emulating 68Ks is nowhere near the heavy lifting PPC emulation entails. Moreover, Classic under OS X is essentially two parts: CPU emulation and hooks to Carbon APIs. The Carbon APIs will still be there in OS x86, and until Apple gets their shit together enough to port the Finder to Cocoa, they don't have a choice. Yes, there'll be endianness issues, but at least they're consistently flipped.
- Apple tells everyone that five years of Classic support is long enough, and that their engineers canna poosh the warp core no moore, cap'n. Childhood's end.
Sometimes, Steve, you gotta do something just because it's cool to be able to, and being able to sell potential switchers on a box that runs not just the last five years' worth of apps but the last ten or fifteen is damned sweet. No one much gives a damn how you do it.
Friday, June 10, 2005
Stage 5: Acceptance.
Bob Cringley just blew his street cred wad. While his perspective on Intel pulling Apple's strings in the future has merit, most of his assumptions don't wash. He's fortunate that so many people are spouting nonsense from all directions right now, that in the future he'll be able to say we were all frightened fools.
"Question 1: What happened to the PowerPC's supposed performance advantage over Intel?"
It's fucking moot if IBM won't develop it any faster or smaller while Intel does both. Three years from now, with 4GHz x86 Intel CPUs on the market, if Apple was still making 2.5GHz Macs and unable to even put those in laptops, sales would flatline.
IBM decided to play it safe on PPC development by throwing in with console gaming where (for now) form factor's irrelevant, chip heat's irrelevant, developers won't embarrass your platform for not advancing, and the public's demands are modest. And they'll succeed anyway, even if they lost a sizeable chunk of mainstream developers.
"Question 2: What happened to Apple's 64-bit operating system?"
Do your fucking homework, Cringely. OS X is largely 32-bit, and programmer guidelines repeatedly discouraged 64-bit dev, in some cases making it impossible (Objective-C won't compile 64-bit code under XCode).
"Question 3: Where the heck is AMD?"
You're SJ and you've just been corporately embarrassed for the third time in your company's history by a chipmaker's whims or lack of ability. Time to switch. Your choices are the following:
"Question 4: Why announce this chip swap a year before it will even begin for customers?"
Translated: "Osborne effect, Osborne effect, Osborne effect." First off, this announcement was at WWDC, not Macworld (where you debut product about to hit shelves). Even if they've busted ass for five years to make the transition easy, they have to tell the coders/manufacturers soon enough to iron out the bugs. There was no way in hell they could have been making these in secret for a year and then spring them on everyone Monday, and dropping the bomb simultaneous to releasing the product is suicide given the limitations of Rosetta.
Apple wants this box to sing, not oink, and that'll take reeducation camp for the remaining CodeWarrior developers who figured they'd never have to migrate to XCode. From Apple's perspective, CodeWarrior = Motorola, and the objective fact is that CW's backed off from both Win/Mac development in favor of embedded systems.
That said, IMO a six month window would have been a smarter compromise; more pressure on small developers, with the implicit assumption that migration isn't all that hard. Given the rumors of how little modding it took Apple to make a G5 box into a Pentium box, it may not take twelve months to retool and go to market.
"Question 5: Is this all really about Digital Rights Management?"
No. Pull your head out of your ass. Apple has much better inside relations with the recording/film industry than Microsoft, and in case you forgot, SJ runs a business which is directly part of the film industry. If the industry demanded that the next gen movie format require a hardware chip to encode and another to decode, there'd be no reason or advantage to make it CPU dependent -- in fact, doing so would make it easier to reverse engineer by crackers, DMCA be damned.
Cringely goes on to say that Intel hates Microsoft. The only thing Intel hates is not having money, and Microsoft can't exactly turn the screws on Intel beyond ensuring that one particular line of processors continues to generate obscene revenues for Intel.
Cringely hints that HP could become Apple's "hardware partner." This one's been pulled out of the woodwork for close to a decade, on par with Tandy becoming Apple's OEM. Somehow I don't see the Taiwanese who make Macs giving much of a damn which yellow haired devils are paying their $2/hour wages, or Apple deriving a particular benefit from this partnership. It's debatable what Apple and HP view as the benefit of selling branded iPods, beyond HP's distribution network (why you can buy iPods at Radio Shack).
Intel has enough money to buy Microsoft, never mind Apple. Antitrust legislation is what keeps them out of the OS market, not missed opportunities or alliances. That doesn't mean they can't milk their relationship with Apple "in Apple's best interest," of course, and it's something SJ expects them to do.
Expect to see Intel pressuring Apple to come out with smaller and smaller devices, and continually providing the hardware to make it possible. You're laughing now, but right now there are $130 battery-powered Linux-based x86 computers on cards small enough to fit inside an iPod Shuffle (or close enough).
Jobs was right, if hurried, about ditching the Newton. Palm did an excellent job stewarding the only platform you can't replace with Linux, but after 10+ years the Palm economy is hurting as it becomes further and further removed from general purpose OSes going into smaller and smaller places. OS development there has stagnated considerably, with nothing new to show each year except more expensive models losing ground to laptops. Palm's splitting its own product line into thirds: disposable contacts managers for students, phones for salesmen, and ur-laptops price competitive with nothing.
Prediction's a fool's game. What I will say is that Jobs saw the trend away from desktops and toward laptops, understood IBM wasn't interested in making that possible for Apple, and Jobs took the only road he could to stay in the game.
If you visualize a 7x10 tablet Mac with a wireless keyboard, a cover that hinges back into an easel for QuickTime 7 theatre DVD playback or Grand Theft Auto pimpin', a more visual jukebox interface for iTunes, and a considerably less junked up Finder, that's your business.
Me, I have a more specific vision of the next WWDC surprise, but I can't say. Too early.
"Question 1: What happened to the PowerPC's supposed performance advantage over Intel?"
It's fucking moot if IBM won't develop it any faster or smaller while Intel does both. Three years from now, with 4GHz x86 Intel CPUs on the market, if Apple was still making 2.5GHz Macs and unable to even put those in laptops, sales would flatline.
IBM decided to play it safe on PPC development by throwing in with console gaming where (for now) form factor's irrelevant, chip heat's irrelevant, developers won't embarrass your platform for not advancing, and the public's demands are modest. And they'll succeed anyway, even if they lost a sizeable chunk of mainstream developers.
"Question 2: What happened to Apple's 64-bit operating system?"
Do your fucking homework, Cringely. OS X is largely 32-bit, and programmer guidelines repeatedly discouraged 64-bit dev, in some cases making it impossible (Objective-C won't compile 64-bit code under XCode).
"Question 3: Where the heck is AMD?"
You're SJ and you've just been corporately embarrassed for the third time in your company's history by a chipmaker's whims or lack of ability. Time to switch. Your choices are the following:
- Blue chip industry leader with zero manufacturing problems and a drooling fascination with your company. Modest current product but secure pipeline.
- Company with brilliant ideas but a lot less time in the business, a shaky record and a snarky CEO responsible for one of those embarrassing episodes.
"Question 4: Why announce this chip swap a year before it will even begin for customers?"
Translated: "Osborne effect, Osborne effect, Osborne effect." First off, this announcement was at WWDC, not Macworld (where you debut product about to hit shelves). Even if they've busted ass for five years to make the transition easy, they have to tell the coders/manufacturers soon enough to iron out the bugs. There was no way in hell they could have been making these in secret for a year and then spring them on everyone Monday, and dropping the bomb simultaneous to releasing the product is suicide given the limitations of Rosetta.
Apple wants this box to sing, not oink, and that'll take reeducation camp for the remaining CodeWarrior developers who figured they'd never have to migrate to XCode. From Apple's perspective, CodeWarrior = Motorola, and the objective fact is that CW's backed off from both Win/Mac development in favor of embedded systems.
That said, IMO a six month window would have been a smarter compromise; more pressure on small developers, with the implicit assumption that migration isn't all that hard. Given the rumors of how little modding it took Apple to make a G5 box into a Pentium box, it may not take twelve months to retool and go to market.
"Question 5: Is this all really about Digital Rights Management?"
No. Pull your head out of your ass. Apple has much better inside relations with the recording/film industry than Microsoft, and in case you forgot, SJ runs a business which is directly part of the film industry. If the industry demanded that the next gen movie format require a hardware chip to encode and another to decode, there'd be no reason or advantage to make it CPU dependent -- in fact, doing so would make it easier to reverse engineer by crackers, DMCA be damned.
Cringely goes on to say that Intel hates Microsoft. The only thing Intel hates is not having money, and Microsoft can't exactly turn the screws on Intel beyond ensuring that one particular line of processors continues to generate obscene revenues for Intel.
Cringely hints that HP could become Apple's "hardware partner." This one's been pulled out of the woodwork for close to a decade, on par with Tandy becoming Apple's OEM. Somehow I don't see the Taiwanese who make Macs giving much of a damn which yellow haired devils are paying their $2/hour wages, or Apple deriving a particular benefit from this partnership. It's debatable what Apple and HP view as the benefit of selling branded iPods, beyond HP's distribution network (why you can buy iPods at Radio Shack).
Intel has enough money to buy Microsoft, never mind Apple. Antitrust legislation is what keeps them out of the OS market, not missed opportunities or alliances. That doesn't mean they can't milk their relationship with Apple "in Apple's best interest," of course, and it's something SJ expects them to do.
Expect to see Intel pressuring Apple to come out with smaller and smaller devices, and continually providing the hardware to make it possible. You're laughing now, but right now there are $130 battery-powered Linux-based x86 computers on cards small enough to fit inside an iPod Shuffle (or close enough).
Jobs was right, if hurried, about ditching the Newton. Palm did an excellent job stewarding the only platform you can't replace with Linux, but after 10+ years the Palm economy is hurting as it becomes further and further removed from general purpose OSes going into smaller and smaller places. OS development there has stagnated considerably, with nothing new to show each year except more expensive models losing ground to laptops. Palm's splitting its own product line into thirds: disposable contacts managers for students, phones for salesmen, and ur-laptops price competitive with nothing.
Prediction's a fool's game. What I will say is that Jobs saw the trend away from desktops and toward laptops, understood IBM wasn't interested in making that possible for Apple, and Jobs took the only road he could to stay in the game.
If you visualize a 7x10 tablet Mac with a wireless keyboard, a cover that hinges back into an easel for QuickTime 7 theatre DVD playback or Grand Theft Auto pimpin', a more visual jukebox interface for iTunes, and a considerably less junked up Finder, that's your business.
Me, I have a more specific vision of the next WWDC surprise, but I can't say. Too early.
Wednesday, June 08, 2005
More like twenty steps backward.
Mac card vendor finds indications x86 Macs likely to use BIOS rather than EFI.
Fuck.
Mac controller card vendor George Rath isn't spelling out his argument clearly enough, so I will. Disclaimer: I'm not a developer, I'm just putting two and two together.
So far Apple's being real tight-lipped on what firmware the x86 Macs will use. Try googling 'BIOS' site:apple.com and after you've sifted through tons of Biography pages, what you'll mostly find is ancient articles referring to the difference between PowerMac and Intel architecture. Google 'EFI' site:apple.com and you'll get references to a color proofing system that uses the same acronym, and a handful of references to OpenDarwin libraries for Extensible Firmware Interface. Good, right?
Wrong. For one thing if you google 'extensible firmware' site:apple.com you get zero hits. Nada. Zilch.
Where the shit hits the fan is here. I'll skip repeating the part in the Apple Universal Binary Specifications which baldly states x86 Macs aren't using Open Firmware (but avoids saying what they are using):
Apple Univ. Binary Tips Ch. 5, Section 7 - "Disk Partitions"
We're left with the following possibilities.
Hopeful: Rushes have led to developer boxes using BIOS, but consumer Macs will use EFI.
Taking a long view: Developer boxes are using EFI but even EFI's advances still require Apple to spell out non-OF partitioning differences.
Pessimistic: Developer boxes are using BIOS, consumer boxes are using BIOS and ultimately we're fucked.
To some extent the die's already cast. A PPC Mac is two things at the same time: GUI Unix and hot iron. An x86 Mac is a pretty OS in a sea of pretty x86 OSes struggling with legacy hardware issues -- except for the other two, most of their apps aren't also spending the next 2 years running at 70% under software emulation. Longhorn can afford to hamstring its performance until IA64 is the norm. Linux sells itself on local compiles and generous variety of readymade builds.
Fuck.
Mac controller card vendor George Rath isn't spelling out his argument clearly enough, so I will. Disclaimer: I'm not a developer, I'm just putting two and two together.
So far Apple's being real tight-lipped on what firmware the x86 Macs will use. Try googling 'BIOS' site:apple.com and after you've sifted through tons of Biography pages, what you'll mostly find is ancient articles referring to the difference between PowerMac and Intel architecture. Google 'EFI' site:apple.com and you'll get references to a color proofing system that uses the same acronym, and a handful of references to OpenDarwin libraries for Extensible Firmware Interface. Good, right?
Wrong. For one thing if you google 'extensible firmware' site:apple.com you get zero hits. Nada. Zilch.
Where the shit hits the fan is here. I'll skip repeating the part in the Apple Universal Binary Specifications which baldly states x86 Macs aren't using Open Firmware (but avoids saying what they are using):
Apple Univ. Binary Tips Ch. 5, Section 7 - "Disk Partitions"
"The partition format of the disk on a Macintosh using an Intel microprocessor differs from that using a PowerPC microprocessor. If your application depends on the partitioning details of the disk, it may not behave as expected. Partitioning details can affect tools that examine the hard disk at a low level."Let's compare this with Amit Singh's older article explaining the difference between OF and BIOS for kernelthread.com, More Power to Firmware (emphasis mine):
The PC partitioning scheme is tied to the BIOS, and is rather inadequate, particularly when it comes to multibooting, or having a large number of partitions. PC partitions may be primary, extended, or logical, with at most 4 primary partitions allowed on a disk. The first (512-byte) sector of a PC disk, the Master Boot Record (MBR), has its 512 bytes divided as follows: 446 bytes for bootstrap code, 64 bytes for four partition table entries of 16 bytes each, and 2 bytes for a signature. Thus, the size of a PC partition table is rather limited, hence the limit on the number of primary partitions. However, one of the primary partitions may be an extended partition, and an arbitrary number of logical partitions could be defined within it. Note that Apple's partitioning scheme is much better in this regard.Or rather, it used to be. About the only sunny side to this is Intel's EFI specification (PDF) which indirectly mentions backwards compatibility to "PC-AT" partitioning schemes.
We're left with the following possibilities.
Hopeful: Rushes have led to developer boxes using BIOS, but consumer Macs will use EFI.
Taking a long view: Developer boxes are using EFI but even EFI's advances still require Apple to spell out non-OF partitioning differences.
Pessimistic: Developer boxes are using BIOS, consumer boxes are using BIOS and ultimately we're fucked.
To some extent the die's already cast. A PPC Mac is two things at the same time: GUI Unix and hot iron. An x86 Mac is a pretty OS in a sea of pretty x86 OSes struggling with legacy hardware issues -- except for the other two, most of their apps aren't also spending the next 2 years running at 70% under software emulation. Longhorn can afford to hamstring its performance until IA64 is the norm. Linux sells itself on local compiles and generous variety of readymade builds.
Tuesday, June 07, 2005
Shiny epaulets.
After careful lobbying on my part, I have been reclassed from Library Specialist to Applications Systems Analyst. The former is a general description which could apply to virtually any clerical/paraprofessional in the building, and in five years I haven't learned dick about librarianship or for that matter worked close to librarians outside of the web development team. As one of my co-workers introduced me to a new hire and tried to explain to her what I did compared to what Brian does, I said, "Brian writes the music, I create the instruments we play it on." Seems pretty accurate to me. After several years doing graphic design, I'm continually surprised with Brian's aptitude with no formal experience or training.
And yes, it comes with a raise, which is good since Ruth plans to stay at home with Maryalee this year. In late 2002, we moved out of the apartment into a house, and this spring we refinanced. No mean feat; my piss turned to ice when I read this week that over 1 in every 3 Arizona mortgages are now interest-only (in 2000 that figure was closer to 1 in 100). FWIW there are apartments in Flagstaff whose rent is higher than our refi'd mortgage payment. It's obscene. Literally, morally obscene.
My duties won't really be changing; what I've been doing for the last few years has fit the new job description better, and it's not arrogant to ask for formal recognition. As in previous jobs, I've piloted innovations and improvements in this position which have benefited everyone and made less work for us down the road. I am fortunate to work with people who appreciate it; I know people who have improved their skills only in spite of being treated badly at work, but they only do so with an eye on their next job elsewhere. Tacked on the corkboard behind my monitor at work is a worn, folded, hand-told half sheet of LaserWriter paper from 1992, handed to me with a job offer for a graphic designer/resume writer position (mentioned in this blog's first entry). 13 years later, I keep that printout as a pointed reminder; in good times it reminds me of how far I've gone. In bad times it reminds me how much tougher things were at one point, and that I survived.
Web standards have come a long way since I started working at Cline Library, and I've striven to adhere to them and maintain browser compatibility, when management would have let me get away with coding the site for IE, with table-based layouts and JavaScript widgets everywhere. Paradoxically as I continue doing my work better, the result gets more and more invisible to the end user. Random content like images used to be hand-coded JavaScripts inlined on the pages, then was refined and externalized and finally replaced altogether with server-side includes harvesting Perl CGIs. Even image-based rollover links are now possible with CSS rather than JavaScript, due to a technique I haven't yet seen elsewhere. The programming component of the job is still there, but it's become a lot subtler.
A current (and ongoing) frustration is with accessibility. My chief motivation for abandoning table based layouts is the amount of extra work it takes to make a complex table layout render in a logical fashion by screen readers. Check out our website in a screen reader or Lynx or a web phone -- it just works. To CSS unaware browsers, the content renders first and the navigation last. It's a common solution now; it wasn't when I suggested it to CSS-discuss 3 years ago.
And yet, screen readers are still hideously primitive. JAWS still refuses to honor the only HTML tag specifically aimed at it, to prevent it from importing screen-only stylesheets, and limits you to using IE. Apple's VoiceOver only works with Safari, and gives every impression of being rushed to market. Opera's reader doesn't automatically read pages when they load, and Opera's designers sincerely believe we're going to return to designing separate XML-based pages requiring a different extension and MIMEtype, only to serve one browser for one platform. All three largely ignore label tags when encountering forms. Despite the label tag being designed as a wrapper for form elements, WAI insists on labels being outside those elements and declared with FOR=ID, and prebuilt sample text in all fields.
The simpler we try to make things for ourselves, the more complex they get. A simple CSS pseudo-selector, :hover, which by W3C spec should be available to all elements, is only available to A links in IE. This limitation is what's kept CSS/unordered list-only dropdown menus off web pages for the last 3 years. A German developer discovered an elegant HTC-based solution which essentially rewrites IE's own handler code to behave according to spec. No alteration of your existing CSS, except for a line of non-spec code all non-IE browsers will ignore.
But if the stylesheet loading the behavior is on a different server than the page requiring it, IE refuses to load the behavior for security reasons -- even though both servers are within the same domain and Microsoft's own documentation is clear that the security restriction is supposed to only apply between domains. After some guessing I found a line of JavaScript which relaxes this restriction.
My predecessor was three times the graphic designer I am. But I think faced with the same problem, he would have stuck with a 3 year old, accessibility unfriendly, 30K noncacheable DHTML solution.
We're doing a retread of the site soon. It won't have the same technical hurdle the prior retread had; abandoning tables, developing CSS layouts, migrating boilerplate to SSI includes... But it refines the prior commitment to CSS and accessibility, with a more hierarchical, centralized and flexible stylesheet, and exploits fluid layouts not possible with IE 5.0 (the leading version during the prior retread). All visible telephone and fax numbers are silently becoming tel: and fax: links, restyled for screen browsers to look like plain text. Anyone browsing with phones now will see the links; selecting them will dial the numbers. We're also making some tougher decisions about graceful degradation across all browsers as Netscape 4 becomes a distant memory and IE 5.0 is nearly unheard of; I detest CSS hacks and those which exploit parser bugs especially. Older online exhibits for Special Collections and Archives are being duplicated and the offline versions converted to CSS and checked against the originals.
And yes, it comes with a raise, which is good since Ruth plans to stay at home with Maryalee this year. In late 2002, we moved out of the apartment into a house, and this spring we refinanced. No mean feat; my piss turned to ice when I read this week that over 1 in every 3 Arizona mortgages are now interest-only (in 2000 that figure was closer to 1 in 100). FWIW there are apartments in Flagstaff whose rent is higher than our refi'd mortgage payment. It's obscene. Literally, morally obscene.
My duties won't really be changing; what I've been doing for the last few years has fit the new job description better, and it's not arrogant to ask for formal recognition. As in previous jobs, I've piloted innovations and improvements in this position which have benefited everyone and made less work for us down the road. I am fortunate to work with people who appreciate it; I know people who have improved their skills only in spite of being treated badly at work, but they only do so with an eye on their next job elsewhere. Tacked on the corkboard behind my monitor at work is a worn, folded, hand-told half sheet of LaserWriter paper from 1992, handed to me with a job offer for a graphic designer/resume writer position (mentioned in this blog's first entry). 13 years later, I keep that printout as a pointed reminder; in good times it reminds me of how far I've gone. In bad times it reminds me how much tougher things were at one point, and that I survived.
Web standards have come a long way since I started working at Cline Library, and I've striven to adhere to them and maintain browser compatibility, when management would have let me get away with coding the site for IE, with table-based layouts and JavaScript widgets everywhere. Paradoxically as I continue doing my work better, the result gets more and more invisible to the end user. Random content like images used to be hand-coded JavaScripts inlined on the pages, then was refined and externalized and finally replaced altogether with server-side includes harvesting Perl CGIs. Even image-based rollover links are now possible with CSS rather than JavaScript, due to a technique I haven't yet seen elsewhere. The programming component of the job is still there, but it's become a lot subtler.
A current (and ongoing) frustration is with accessibility. My chief motivation for abandoning table based layouts is the amount of extra work it takes to make a complex table layout render in a logical fashion by screen readers. Check out our website in a screen reader or Lynx or a web phone -- it just works. To CSS unaware browsers, the content renders first and the navigation last. It's a common solution now; it wasn't when I suggested it to CSS-discuss 3 years ago.
And yet, screen readers are still hideously primitive. JAWS still refuses to honor the only HTML tag specifically aimed at it, to prevent it from importing screen-only stylesheets, and limits you to using IE. Apple's VoiceOver only works with Safari, and gives every impression of being rushed to market. Opera's reader doesn't automatically read pages when they load, and Opera's designers sincerely believe we're going to return to designing separate XML-based pages requiring a different extension and MIMEtype, only to serve one browser for one platform. All three largely ignore label tags when encountering forms. Despite the label tag being designed as a wrapper for form elements, WAI insists on labels being outside those elements and declared with FOR=ID, and prebuilt sample text in all fields.
The simpler we try to make things for ourselves, the more complex they get. A simple CSS pseudo-selector, :hover, which by W3C spec should be available to all elements, is only available to A links in IE. This limitation is what's kept CSS/unordered list-only dropdown menus off web pages for the last 3 years. A German developer discovered an elegant HTC-based solution which essentially rewrites IE's own handler code to behave according to spec. No alteration of your existing CSS, except for a line of non-spec code all non-IE browsers will ignore.
But if the stylesheet loading the behavior is on a different server than the page requiring it, IE refuses to load the behavior for security reasons -- even though both servers are within the same domain and Microsoft's own documentation is clear that the security restriction is supposed to only apply between domains. After some guessing I found a line of JavaScript which relaxes this restriction.
My predecessor was three times the graphic designer I am. But I think faced with the same problem, he would have stuck with a 3 year old, accessibility unfriendly, 30K noncacheable DHTML solution.
We're doing a retread of the site soon. It won't have the same technical hurdle the prior retread had; abandoning tables, developing CSS layouts, migrating boilerplate to SSI includes... But it refines the prior commitment to CSS and accessibility, with a more hierarchical, centralized and flexible stylesheet, and exploits fluid layouts not possible with IE 5.0 (the leading version during the prior retread). All visible telephone and fax numbers are silently becoming tel: and fax: links, restyled for screen browsers to look like plain text. Anyone browsing with phones now will see the links; selecting them will dial the numbers. We're also making some tougher decisions about graceful degradation across all browsers as Netscape 4 becomes a distant memory and IE 5.0 is nearly unheard of; I detest CSS hacks and those which exploit parser bugs especially. Older online exhibits for Special Collections and Archives are being duplicated and the offline versions converted to CSS and checked against the originals.
Monday, June 06, 2005
Apple: The Road Ahead
Christ almighty. Keynote speech is over, and the worst has been confirmed. PPC is effectively dead and Marklar is the future of the Mac platform. Tiger demoed on a stock x86, not a word about proprietary hardware.
Apple's and Intel's press release pages are glowing. I don't think my brother who just bought a Powerbook is going to be glowing. The $2500 I sunk 18 months ago into a dual G5 isn't leaving me glowing. I can't imagine the salesfloor staff at Apple stores are cheering, either. Even with a 2 year transition period and all the promises in the world that apps will ship with fat binaries, I can't see PPC Mac sales remaining positive before the Intel boxes are shipping.
Here's what I can't understand.
Apple's entire business model is selling turnkey systems. Computers you don't need to be smart to use, music players an idiot could load and play. Note the emphasis on nouns referring to hardware, hardware that doesn't have clones. In other words, you want the Apple experience, you have to buy the Apple hardware to run it on. And Apple turns a tidy profit selling that hardware, and effectively killed the clone market when it started to dilute their sales.
So, if Leopard is going to run on generic x86 hardware, how does Apple make money when their OS can run on Joe Schmuck's Alienware box and Joe's busy getting Leopard off P2P? Apple's only current software revenue stream is OS upgrades and niche video editing software.
Presumably Intel's recent news about chip level DRM could make it impossible to pirate Longhorn/Leopard, but I don't know.
Second thing: this is putting Apple's feet to the fire on the matter of whether OS X is actually more secure than Windows. Now that OS X will run on stock x86es, how many existing x86 virii will be retooled slightly for it? Is the gamble that virus authors won't bother trying to crack a niche OS, and by the time that its market share is significant enough to be attractive, the OS will be so robust as to make the prospect daunting?
Nothing makes sense any more.
By predicting the future based on what's reasonable, I seem to consistently alter it for the worse. So, here's my "bad rice" prediction.
To Apple's dismay, the mainstream media will not trumpet this as a Good Thing. The blogosphere will be filled with hate, fear and confusion, and the mocking laughter of Apple-bashers. Angry, embittered Mac loyalists will divide between flocking to Windows and Linux, where their financial investments are minimal.
Without any regulation from Republicans in Washington, Microsoft will continue patenting everything and start using the courts to effectively destroy open source. Our future trade agreements with the EU will not-so-thinly imply that not following suit will be considered an act of war. Linux will disappear outside of China.
Within five years Steve Jobs will get on stage and wax about Apple's bright future, right before Bill Gates walks out of the curtains and they jointly tell us MS bought them out, but not to worry, "we have a firm commitment to the future of OS X." Within another twelve months MS management decisions will convince Apple developers to jump ship, and MS stockholders will snuff Apple.
Overnight, Microsoft will "purchase" System V UNIX from their holding company SCO. Congress will pass murkily-worded IP legislation further putting the nails in the coffins of non-commercial licenses, and Microsoft will exploit it to effectively criminalize the existence of FreeBSD, and most likely extort a promise from OpenOffice that it no longer read or write Microsoft formats. The EFF will bankrupt itself trying to defend cases like these; the few that make it to SCOTUS will see Bush appointees ruling solidly in favor of the ownership society.
With naysayers telling us that it couldn't happen, everything will become a monoculture: processors, formats, OS. Windows will transition to a POSIX infrastructure, but they'll have free rein to bastardize its compliance beyond recognition.
This is supposed to be my 12th wedding anniversary. I feel utterly fucked.
Apple's and Intel's press release pages are glowing. I don't think my brother who just bought a Powerbook is going to be glowing. The $2500 I sunk 18 months ago into a dual G5 isn't leaving me glowing. I can't imagine the salesfloor staff at Apple stores are cheering, either. Even with a 2 year transition period and all the promises in the world that apps will ship with fat binaries, I can't see PPC Mac sales remaining positive before the Intel boxes are shipping.
Here's what I can't understand.
Apple's entire business model is selling turnkey systems. Computers you don't need to be smart to use, music players an idiot could load and play. Note the emphasis on nouns referring to hardware, hardware that doesn't have clones. In other words, you want the Apple experience, you have to buy the Apple hardware to run it on. And Apple turns a tidy profit selling that hardware, and effectively killed the clone market when it started to dilute their sales.
So, if Leopard is going to run on generic x86 hardware, how does Apple make money when their OS can run on Joe Schmuck's Alienware box and Joe's busy getting Leopard off P2P? Apple's only current software revenue stream is OS upgrades and niche video editing software.
Presumably Intel's recent news about chip level DRM could make it impossible to pirate Longhorn/Leopard, but I don't know.
Second thing: this is putting Apple's feet to the fire on the matter of whether OS X is actually more secure than Windows. Now that OS X will run on stock x86es, how many existing x86 virii will be retooled slightly for it? Is the gamble that virus authors won't bother trying to crack a niche OS, and by the time that its market share is significant enough to be attractive, the OS will be so robust as to make the prospect daunting?
Nothing makes sense any more.
By predicting the future based on what's reasonable, I seem to consistently alter it for the worse. So, here's my "bad rice" prediction.
To Apple's dismay, the mainstream media will not trumpet this as a Good Thing. The blogosphere will be filled with hate, fear and confusion, and the mocking laughter of Apple-bashers. Angry, embittered Mac loyalists will divide between flocking to Windows and Linux, where their financial investments are minimal.
Without any regulation from Republicans in Washington, Microsoft will continue patenting everything and start using the courts to effectively destroy open source. Our future trade agreements with the EU will not-so-thinly imply that not following suit will be considered an act of war. Linux will disappear outside of China.
Within five years Steve Jobs will get on stage and wax about Apple's bright future, right before Bill Gates walks out of the curtains and they jointly tell us MS bought them out, but not to worry, "we have a firm commitment to the future of OS X." Within another twelve months MS management decisions will convince Apple developers to jump ship, and MS stockholders will snuff Apple.
Overnight, Microsoft will "purchase" System V UNIX from their holding company SCO. Congress will pass murkily-worded IP legislation further putting the nails in the coffins of non-commercial licenses, and Microsoft will exploit it to effectively criminalize the existence of FreeBSD, and most likely extort a promise from OpenOffice that it no longer read or write Microsoft formats. The EFF will bankrupt itself trying to defend cases like these; the few that make it to SCOTUS will see Bush appointees ruling solidly in favor of the ownership society.
With naysayers telling us that it couldn't happen, everything will become a monoculture: processors, formats, OS. Windows will transition to a POSIX infrastructure, but they'll have free rein to bastardize its compliance beyond recognition.
This is supposed to be my 12th wedding anniversary. I feel utterly fucked.
Wednesday, June 01, 2005
Open Letter To Dreamweaver Development Team
As a general rule I think Dreamweaver rules. I've been using it since 3.0 and it's still the best Win/Mac site development tool there is. It won't arbitrarily rewrite your code like Netscape Composer/Nvu or FrontPage, and it doesn't default to creating browser-centric code like FP. Its JavaScript based framework (preceding Firefox's conception by years) has allowed many useful extensions to be added (disclaimer: I wrote some rather modest extensions myself). They worked most of the kinks out of the FTP problems.
It still hits the brick wall on one issue. Site-root-relative URLs. URLs typically fall into three types:
In a campus environment we're a lot less likely to use a local/remote FTP model for site management and a lot more likely to map the servers to local drives.
My personal space on the campus staff server is /webhome/ar24/public_html/ which equates to http://www2.nau.edu/~ar24. I have privs to map my public_html to a drive, G:\
[No sysadmin in their right mind would give me privs to map /webhome/ directly, and even if they did, every time I opened DW's Files tab it would slow down to a crawl trying to refresh its internal listing.]
I create a site in DW using G:\clockwork\ as the Local Root Folder and http://www2.nau.edu/~ar24/clockwork/ as its HTTP address just as I should. Inside my site are the following:
http://www2.nau.edu/~ar24/clockwork/pages/yarbles.html
http://www2.nau.edu/~ar24/clockwork/images/alex.gif
http://www2.nau.edu/~ar24/clockwork/moloko.css
yarbles.html links to the stylesheet at src="/moloko.css" and has an image link where src="/~ar24/clockwork/images/alex.gif".
In Display View, the stylesheet will be applied but the image comes through as a broken link. When I view the page in a browser using http://www2.nau.edu/~ar24/clockwork/pages/yarbles.html the exact opposite happens; the image comes through but the stylesheet is not applied. Why?
Because DW's Display View pseudo-browser renderer only understands your local site topology.
It doesn't see a ~ar24 directory below G:\ so it assumes the URL is incorrect. It does see a moloko.css at the "root" of G:\ so it wrongly imports the stylesheet.
Second real-world example: the Cline Library website at http://www.nau.edu/library. In reality www.nau.edu is on one server (mutt) and www.nau.edu/library is on another (jeff), where /library redirects to jeff's root-level /public_html. This is far more common than you might think.
In this case we've mapped jeff's entire root to a local drive H:\ and created the DW site at H:\public_html\, being sure to define http://www.nau.edu/library/ as the site URL. However, remember that valid SSR URLs must start with /library/ because the server delivering the pages is still using this bit of redirection.
So, a page with a correct SSR link to an image at /library/images/logo.png will fail in Design View because H:\ doesn't have a /library. An incorrect link to /images/logo.png will show the image in Design View but fail in the real world.
In both cases DW's Design View fails because it can't conceive of a site root corresponding to anything except a URL directory coming immediately after the domain name. And strictly speaking, it doesn't have enough information to reliably make that call.
All it would require of DW to correctly resolve SSR URLs is one more site definition field: the relative SSR URL equivalent to the local root folder. Prototype below:
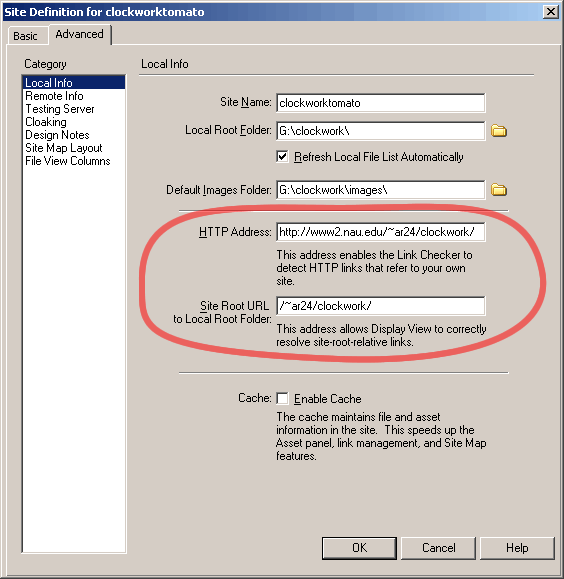
Note to engineers: I'm aware that this means parsing work for "Preview in Browser," since PiB serves file: rather than http: tempfiles to browsers, and SRR URLs are unreliable inside file:-browsed pages. However, the above dialog gives DW everything it needs to replace SRR URLs with relative URLs in the tempfile. Considering that PiB routinely simulates server behaviors by inserting/substituting content, this isn't exactly asking you to forge new territory.
I respect completely that DW gives a lot of support to relative linking, e.g. moving files around in the File browser automatically updating those links. I also think this functionality is being used as a crutch to avoid implementing a standard many web developers have asked for, and whether or not Macromedia likes it, the future of content management includes pages being moved around, independently of Dreamweaver.
More importantly, if a site has a clear definition of the relationship between URL and local site root, there aren't any more excuses why resources inside the site root linked to with an absolute URL cannot display in Design View. This is string comparison, not DNS resolution, and a 7 year old product should be expected to understand it.
It still hits the brick wall on one issue. Site-root-relative URLs. URLs typically fall into three types:
- Absolute
<img src="http://www.nau.edu/library/images/doggy.png" />
Upside: Excellent for guaranteeing stable links; can be used everywhere in your site.
Downfall: Dependent on you never changing your domain. DW's Display View won't resolve them and shows you broken image links (or in the case of stylesheets, they aren't applied). - Document-relative
<img src="../images/doggy.png" />
Upside: short, easy for DW to understand and display correctly in DV. Portable if you change a site's server/domain.
Downfall: unless you only move pages inside DW's own file manager these links break. - Site-root-relative
<img src="/library/images/doggy.png" />
Upside: all the stability of absolute links, with document-relative's domain agnosticism.
Downfall: DW is incredibly stupid about resolving these in Display View because it considers that URL to be relative to the top of your local site root instead of resolving it relative to server.domain.tld like every browser on the planet since the beginning of the internet.
In a campus environment we're a lot less likely to use a local/remote FTP model for site management and a lot more likely to map the servers to local drives.
My personal space on the campus staff server is /webhome/ar24/public_html/ which equates to http://www2.nau.edu/~ar24. I have privs to map my public_html to a drive, G:\
[No sysadmin in their right mind would give me privs to map /webhome/ directly, and even if they did, every time I opened DW's Files tab it would slow down to a crawl trying to refresh its internal listing.]
I create a site in DW using G:\clockwork\ as the Local Root Folder and http://www2.nau.edu/~ar24/clockwork/ as its HTTP address just as I should. Inside my site are the following:
http://www2.nau.edu/~ar24/clockwork/pages/yarbles.html
http://www2.nau.edu/~ar24/clockwork/images/alex.gif
http://www2.nau.edu/~ar24/clockwork/moloko.css
yarbles.html links to the stylesheet at src="/moloko.css" and has an image link where src="/~ar24/clockwork/images/alex.gif".
In Display View, the stylesheet will be applied but the image comes through as a broken link. When I view the page in a browser using http://www2.nau.edu/~ar24/clockwork/pages/yarbles.html the exact opposite happens; the image comes through but the stylesheet is not applied. Why?
Because DW's Display View pseudo-browser renderer only understands your local site topology.
It doesn't see a ~ar24 directory below G:\ so it assumes the URL is incorrect. It does see a moloko.css at the "root" of G:\ so it wrongly imports the stylesheet.
Second real-world example: the Cline Library website at http://www.nau.edu/library. In reality www.nau.edu is on one server (mutt) and www.nau.edu/library is on another (jeff), where /library redirects to jeff's root-level /public_html. This is far more common than you might think.
In this case we've mapped jeff's entire root to a local drive H:\ and created the DW site at H:\public_html\, being sure to define http://www.nau.edu/library/ as the site URL. However, remember that valid SSR URLs must start with /library/ because the server delivering the pages is still using this bit of redirection.
So, a page with a correct SSR link to an image at /library/images/logo.png will fail in Design View because H:\ doesn't have a /library. An incorrect link to /images/logo.png will show the image in Design View but fail in the real world.
In both cases DW's Design View fails because it can't conceive of a site root corresponding to anything except a URL directory coming immediately after the domain name. And strictly speaking, it doesn't have enough information to reliably make that call.
All it would require of DW to correctly resolve SSR URLs is one more site definition field: the relative SSR URL equivalent to the local root folder. Prototype below:
Note to engineers: I'm aware that this means parsing work for "Preview in Browser," since PiB serves file: rather than http: tempfiles to browsers, and SRR URLs are unreliable inside file:-browsed pages. However, the above dialog gives DW everything it needs to replace SRR URLs with relative URLs in the tempfile. Considering that PiB routinely simulates server behaviors by inserting/substituting content, this isn't exactly asking you to forge new territory.
I respect completely that DW gives a lot of support to relative linking, e.g. moving files around in the File browser automatically updating those links. I also think this functionality is being used as a crutch to avoid implementing a standard many web developers have asked for, and whether or not Macromedia likes it, the future of content management includes pages being moved around, independently of Dreamweaver.
More importantly, if a site has a clear definition of the relationship between URL and local site root, there aren't any more excuses why resources inside the site root linked to with an absolute URL cannot display in Design View. This is string comparison, not DNS resolution, and a 7 year old product should be expected to understand it.
Saturday, May 28, 2005
Making DVDs without pro apps revisited
In a previous post I learned the hard way that making compilation DVDs with Final Cut from source movies has the unwanted time/disk space baggage of reprocessing, and FC's highly finicky nature about the KHz of the clips. I also learned that QT Pro does a jim-dandy job of snipping out commercials and saving short reference movies for iDVD.
Which brings me to the next challenge. By default iDVD considers separate movie clips dropped into it as, well, separate. Click one and it plays, but at the end it returns to the main menu instead of continuing to the next, the way you'd expect chapters to play on a theatrical DVD. And there's no "play all" option.
In order for iDVD to consider clips as being linear chunks of a sequence, they have to be linear chunks in a sequence when dropped into iDVD. If iDVD doesn't see chapter markers in a file dropped into it, it considers them self-contained, unsubdividable sequences.
If you don't have Final Cut, you've got two options for making chapter markers. Prior to iMovie HD, you had to have QT Pro, a text editor, an understanding of QT's caption markup language, and the patience of a saint. And enough time and disk space to export a separate, self-contained movie of the original movies put together in order. It's time consuming and may crash at the 98% complete point. Oh, and there's a pretty good chance iDVD won't recognize the chapter titles if anything's amiss. Suddenly FC's razorblade icon starts suggesting its other popular connotation.
iMovie HD offers a simpler solution. As before, edit your source clips in QT Pro, save reference movies, and then open a new iMovie project. Drop the reference movies into iMovie's timeline in your preferred order, then click the iDVD button. A list window appears; click each movie clip then click "Add Chapter." Then click "Create iDVD Project" and iMovie does the dirty work for you, silently building a chaptered reference movie and dropping it into a new iDVD project. Main menu title screen with "Play All/Select Chapter" options, and a second page with the default chapter metaphor (e.g. freezeframes of the chapter beginning).
As a test I did this reusing the clips from the last DVD project I built. The first three movie clips came in lickety split... ...then the fourth sprung the dreaded "Importing Files" dropdown, with an import time longer than the clip. I cancelled it and tried the fifth clip. Same result. Why? Is there some "honeymoon" limit of roughly 60 minutes before imports go to hell? I doubt it.
As it so happens the first three clips were 20-minute reference movies saved from original 32-minute movies. The fourth and fifth were 20-minute reference movies saved from the same original 62-minute movie. I suspect iMovie's import speed is proportional to the number of edits from the source movie. Interestingly enough, after import the aspect ratio on the two clips is squashed with black TV-safe margins above and below.
We'll see how the final movies come out. If this technique works I have a vastly improved workflow for my MST3K conversion process.
Unusual note: I was testing how well the H.264 codec performs when I noticed shit-awful levels of flicker. At first I was inclined to blame the codec itself, but when getting info on the samples I saw they had fps rates of 11 and 14 instead of the 29.97 AlchemyTV was told to capture. The clearly visible frame overlap in freeze frames proves it.
So, the question of the day is what's changing the framerate?
Which brings me to the next challenge. By default iDVD considers separate movie clips dropped into it as, well, separate. Click one and it plays, but at the end it returns to the main menu instead of continuing to the next, the way you'd expect chapters to play on a theatrical DVD. And there's no "play all" option.
In order for iDVD to consider clips as being linear chunks of a sequence, they have to be linear chunks in a sequence when dropped into iDVD. If iDVD doesn't see chapter markers in a file dropped into it, it considers them self-contained, unsubdividable sequences.
If you don't have Final Cut, you've got two options for making chapter markers. Prior to iMovie HD, you had to have QT Pro, a text editor, an understanding of QT's caption markup language, and the patience of a saint. And enough time and disk space to export a separate, self-contained movie of the original movies put together in order. It's time consuming and may crash at the 98% complete point. Oh, and there's a pretty good chance iDVD won't recognize the chapter titles if anything's amiss. Suddenly FC's razorblade icon starts suggesting its other popular connotation.
iMovie HD offers a simpler solution. As before, edit your source clips in QT Pro, save reference movies, and then open a new iMovie project. Drop the reference movies into iMovie's timeline in your preferred order, then click the iDVD button. A list window appears; click each movie clip then click "Add Chapter." Then click "Create iDVD Project" and iMovie does the dirty work for you, silently building a chaptered reference movie and dropping it into a new iDVD project. Main menu title screen with "Play All/Select Chapter" options, and a second page with the default chapter metaphor (e.g. freezeframes of the chapter beginning).
As a test I did this reusing the clips from the last DVD project I built. The first three movie clips came in lickety split... ...then the fourth sprung the dreaded "Importing Files" dropdown, with an import time longer than the clip. I cancelled it and tried the fifth clip. Same result. Why? Is there some "honeymoon" limit of roughly 60 minutes before imports go to hell? I doubt it.
As it so happens the first three clips were 20-minute reference movies saved from original 32-minute movies. The fourth and fifth were 20-minute reference movies saved from the same original 62-minute movie. I suspect iMovie's import speed is proportional to the number of edits from the source movie. Interestingly enough, after import the aspect ratio on the two clips is squashed with black TV-safe margins above and below.
We'll see how the final movies come out. If this technique works I have a vastly improved workflow for my MST3K conversion process.
Unusual note: I was testing how well the H.264 codec performs when I noticed shit-awful levels of flicker. At first I was inclined to blame the codec itself, but when getting info on the samples I saw they had fps rates of 11 and 14 instead of the 29.97 AlchemyTV was told to capture. The clearly visible frame overlap in freeze frames proves it.
So, the question of the day is what's changing the framerate?
Monday, May 23, 2005
Gentrification
It's one thing to crow about the virtues of designing web sites using XHTML/CSS instead of HTML4 tables and JavaScript. It's another to go back to one of your own Frankenstein jobs and fix it.
The Bert Lauzon exhibit was one of two I inherited midstream from my predecessor, a talented graphic designer named Bob Lunday. Bob set the tone for what exhibits could look like. However, when he left NAU for W.L. Gore in late 1999, Dreamweaver 3 was teh hotness, and Web design was largely a matter of building tables.
The magnifier pane is an excellent example of a concept not ready for the real world. Invariably the demos are on pages which aren't long enough to scroll, so the issue of dynamically calculating the offset of the pane from the thumbnail never comes into play.
Typically when I find a JS widget from someone else, there's a honeymoon period followed by the stark truth of how easily it breaks when just a few basic assumptions in the original design are challenged with real world requirements. Recently a charming little script for automatically checking/unchecking all the boxes in a form met the real-world problem of what happens when half those boxes are divided visually from the other half, but share the same NAME value (e.g. separate fieldsets). The code had to be rewritten to take a container ID and use a different method for collecting the INPUT objects.
Back to the magnifier pane. With the thumbnail in an unknown position, I had to rewrite the code to account for the pane's location. At the time, the 4.0 browsers were dominant. It would be nostalgic to say the differences in the dialects were mostly semantic; the truth is the object models diverged unpleasantly, and the dialects reflected different paradigms. My "force relative position" script in the body onload discovered each thumbnail's coordinates, then repositioned the pane relative to the thumbnail. This was complicated by the limitation that IE 4 only returned the coordinates of an HTML element relative to its container element, not the page, so if the image was in a table (like all of them are in the exhibit), the script had to be modified to take the container ID as well. If IE was detected the table's coordinates were determined instead and then the thumbnail's offset from the table was fudged to create the image coordinates.
In its 2000 incarnation, the magnifier pane breaks in all modern browsers, whose script engines expect DOM models for event capture, object referencing and style property names. This is actually a good thing. The challenge was finding a modernized version of the magnifier pane, since the original author seems to have forsaken it. Thankfully someone at Princeton either wrote or found a fix which cooperates in IE/Moz/Opera/Safari (but not in Konqueror). Its only drawback is that in IE under W2K the pane blanks while you drag it—most likely due to its method of overloading all BODY drag behaviors (thinking like OOP rather than procedural code). Under XP it's fine.
The rest of the Lauzon exhibit still requires reworking. Completed so far:
The Bert Lauzon exhibit was one of two I inherited midstream from my predecessor, a talented graphic designer named Bob Lunday. Bob set the tone for what exhibits could look like. However, when he left NAU for W.L. Gore in late 1999, Dreamweaver 3 was teh hotness, and Web design was largely a matter of building tables.
- Websites were designed in Photoshop, chopped in ImageReady into tables and given over to DW for cleaning up the aftermath.
- JavaScript rollovers were everywhere, along with image preloaders. At a time when most people still had dialup connections I can't explain what we were
smokingthinking. - We were just beginning to figure out that using the LAYER tag wasn't such a good idea.
- CSS was used mainly for link text rollover effects in IE since Netscape wouldn't support it until 6.0 came out, and Netscape 4's CSS model was eight kinds of broken.
- We duplicated everything across every page — scripts, rudimentary CSS, BODY formatting, everything. Possible exception for long script modules.
- JavaScripts were written for Netscape 4 or IE 4, both of which used dialects soon to be obsolete, and browser sniffing and code forking was everywhere. DHTML authors were the only ones working on universal wrapper functions, which as they metastasized from functions into entire libraries, eventually became more of a problem than a solution.
- Most JavaScripts looked more like BASIC-Plus than object-oriented code because conceptually most script authors weren't coming from C++ or Java backgrounds and didn't recognize the potential or good programming practices.
The magnifier pane is an excellent example of a concept not ready for the real world. Invariably the demos are on pages which aren't long enough to scroll, so the issue of dynamically calculating the offset of the pane from the thumbnail never comes into play.
Typically when I find a JS widget from someone else, there's a honeymoon period followed by the stark truth of how easily it breaks when just a few basic assumptions in the original design are challenged with real world requirements. Recently a charming little script for automatically checking/unchecking all the boxes in a form met the real-world problem of what happens when half those boxes are divided visually from the other half, but share the same NAME value (e.g. separate fieldsets). The code had to be rewritten to take a container ID and use a different method for collecting the INPUT objects.
Back to the magnifier pane. With the thumbnail in an unknown position, I had to rewrite the code to account for the pane's location. At the time, the 4.0 browsers were dominant. It would be nostalgic to say the differences in the dialects were mostly semantic; the truth is the object models diverged unpleasantly, and the dialects reflected different paradigms. My "force relative position" script in the body onload discovered each thumbnail's coordinates, then repositioned the pane relative to the thumbnail. This was complicated by the limitation that IE 4 only returned the coordinates of an HTML element relative to its container element, not the page, so if the image was in a table (like all of them are in the exhibit), the script had to be modified to take the container ID as well. If IE was detected the table's coordinates were determined instead and then the thumbnail's offset from the table was fudged to create the image coordinates.
In its 2000 incarnation, the magnifier pane breaks in all modern browsers, whose script engines expect DOM models for event capture, object referencing and style property names. This is actually a good thing. The challenge was finding a modernized version of the magnifier pane, since the original author seems to have forsaken it. Thankfully someone at Princeton either wrote or found a fix which cooperates in IE/Moz/Opera/Safari (but not in Konqueror). Its only drawback is that in IE under W2K the pane blanks while you drag it—most likely due to its method of overloading all BODY drag behaviors (thinking like OOP rather than procedural code). Under XP it's fine.
The rest of the Lauzon exhibit still requires reworking. Completed so far:
- 2-row, 1-column image/caption tables have been changed to 1-cell tables with CAPTION elements (not a perfect solution, but until HTML has rendered caption metadata for image tags this is it).
- JavaScript rollover image buttons are now completely CSS, utilizing a transparent IMG trick I recently developed (and haven't seen duplicated elsewhere). The default button image is a transparent single-pixel GIF stretched to the background image's dimensions; a hover behavior on the link overrides the background image. Cross browser compatible without csshover.
- The remaining table formatting is mostly replaced with CSS and more syntactically meaningful code. Bert Lauzon's diary entries are BLOCKQUOTEs.
- The image of W.W. Bass' classified newspaper advertisement has been given a LONGDESC pointing to a separate web page containing a reasonable simulation in CSS. I haven't seen any formal declarations stating that LONGDESC pages are supposed to avoid any CSS markup, so for now it isn't cheating.
Saturday, May 21, 2005
How not to make DVDs of your favorite TV shows
What I've been doing for close to a year now is capturing shows with AlchemyTV DVR to .MOVs on my hard drive, then editing out commercials in Final Cut Express 1.0.1, exporting .MOV and dropping into iDVD.
For a while it seemed to work great. However, we began to notice that the audio sync was slightly off in a few places. Doing some tech searching it was strongly suggested that drift could be caused by capturing video to your startup HD.
So, we bought a second internal ATA Maxtor and changed all of AlchemyTV's and Final Cut's settings to do nothing with the startup disk and do everything in the second disk. For a while that worked, too, but soon we began to see the same problem in our DVDs.
So, I optimized the second HD before all DVD projects. No go. Out of curiosity I looked at the FC export .MOV (which QT 6 could not play, but QT 7 can) -- the drift was there. In the export. The original .MOVs were fine. So, I experimented with different recording codecs. No dice. Some movies came into FC fine, others came in with noticeable sync problems, even before export.
After bothering FC experts in a forum, they gave several suggestions:
If I needed professional video effects this would be a real problem. But for the home user who's just making DVDs of their favorite shows or dubbing from old VHS, QT Pro is all the tool you need, and you'll avoid an unnecessary extra transcoding before burning.
For a while it seemed to work great. However, we began to notice that the audio sync was slightly off in a few places. Doing some tech searching it was strongly suggested that drift could be caused by capturing video to your startup HD.
So, we bought a second internal ATA Maxtor and changed all of AlchemyTV's and Final Cut's settings to do nothing with the startup disk and do everything in the second disk. For a while that worked, too, but soon we began to see the same problem in our DVDs.
So, I optimized the second HD before all DVD projects. No go. Out of curiosity I looked at the FC export .MOV (which QT 6 could not play, but QT 7 can) -- the drift was there. In the export. The original .MOVs were fine. So, I experimented with different recording codecs. No dice. Some movies came into FC fine, others came in with noticeable sync problems, even before export.
After bothering FC experts in a forum, they gave several suggestions:
- FC isn't meant to work with anything other than pristine DV straight out of a DV-cam.
- QT movies not from DV-cams don't guarantee 48.000KHz recording rates and FC, unlike QT Player, isn't capable of dealing with less than perfection. The irony here is that Linux developers have known for years that consumer Canon DV-cams don't output perfect 48.000 and Apple's had to write code to compensate for it for years.
If I needed professional video effects this would be a real problem. But for the home user who's just making DVDs of their favorite shows or dubbing from old VHS, QT Pro is all the tool you need, and you'll avoid an unnecessary extra transcoding before burning.
Subscribe to:
Posts (Atom)



{kind=link}